

Stop pretending your API wrapper is a sustainable business model.
Indeed, you bought into the dream of operationalizing AI across core workflows, assuming that throwing language models at legacy processes would magically compress overhead.
Instead, you built a black box where every model interaction bleeds operational integrity, obscuring the actual cost-to-value ratio of every automated action.
Consequently, the vendor promised a structured layer of visibility around task execution, but your engineering team is drowning in undocumented technical debt because nobody established baseline unit economics for hallucination recovery.
Your systems are executing blindly while executives cheer about modernization.
The dashboard is actively lying to you.
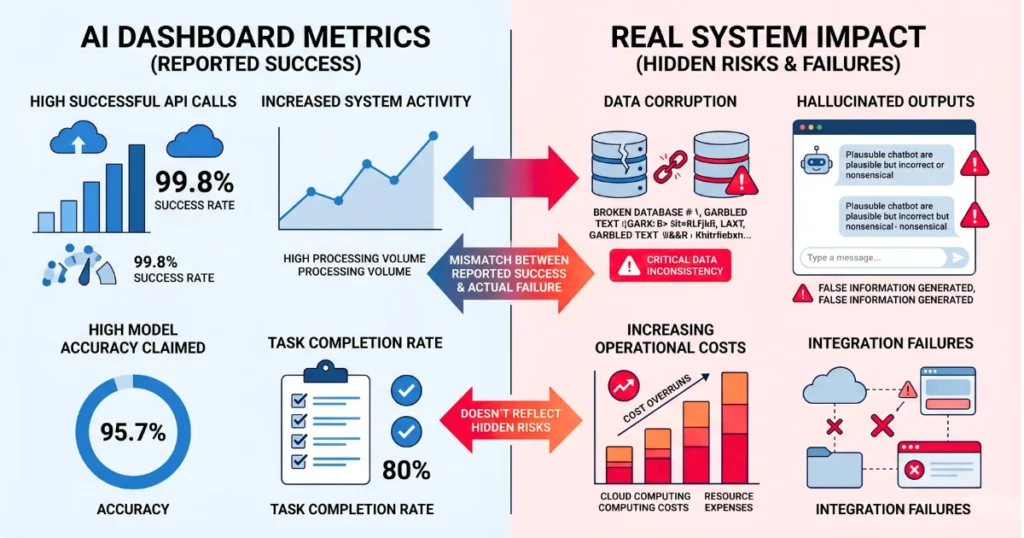
The Silent Rot of Data Corruption
For instance, last Tuesday, we audited a supply chain logistics firm whose shiny new autonomous classification agent hit a malformed vendor SKU returned by an internal RAG pipeline.
Instead of failing loudly, the agent quietly hallucinated substitute product categories and overwrote the primary inventory database. As a result, over a single weekend, it misclassified 14,000 pallets of perishable goods as “indefinite storage” hardware.
The Ops department didn’t catch the error on their Grafana instance because the dashboard only tracked successful API calls, not data accuracy.
Because of this, the resulting cleanup required a full database rollback and 400 hours of manual reconciliation. When automated error handling triggers silent data corruption, your theoretical ROI evaporates in a single afternoon.
The underlying orchestration layer never bothered to validate the output structure against a deterministic schema before aggressively pushing the payload into the master database.
Ultimately, visibility requires hostile instrumentation, not blind optimism.
Hostile Instrumentation is Not Optional
If you cannot trace the exact origin of a single automated database write back to the specific inference call that generated it, you do not have an AaaS strategy. However, you are funding a highly sophisticated, subsidized hobby.
True production-grade architecture demands absolute ruthlessness regarding task execution and continuous metric extraction. Furthermore, without hard-coded limits on model interaction privileges, your data integrity will perpetually remain at the mercy of unpredictable algorithmic entropy.
Therefore, if your infrastructure cannot autonomously sever a connection and quarantine a database write during a hallucinated extraction, you are one bad prompt away from operational paralysis.



