
If you’re a developer or technical founder wondering “what is RAG in AI?”, it’s worth starting with a real mistake.
Specifically, a couple of years ago, my team built an internal HR chatbot for a mid-sized company. We loaded hundreds of employee handbooks and policy PDFs into a vector database, assuming the AI would “figure it out.”
Unfortunately, it didn’t.
Instead, the system confidently told a pregnant employee she had zero days of maternity leave. Consequently, it had pulled a random line from an outdated contractor agreement rather than the latest policy.
That single mistake broke user trust, created legal risk, and burned through our API budget in days.
Undoubtedly, this is the reality of AI in production. It’s not magic—it’s engineering. Therefore, that’s exactly where Retrieval-Augmented Generation (RAG) comes in.
Why Standard AI Models Fail (And Hallucinate)
Modern AI models like ChatGPT or Gemini don’t actually “know” your data. Because they are trained on historical datasets, they suffer from knowledge cutoffs and cannot access private company information. Furthermore, these models generate answers based on probability, not objective truth.
When they don’t know something, they rarely say “I don’t know.” Rather, they guess.
As a result, this is what we call AI hallucination—a confident, well-written, but completely incorrect answer. (If you want to understand the mechanics behind this, it helps to realize why AI “hallucinations” are a feature, not a bug).
What is RAG in AI? (Simple Explanation)
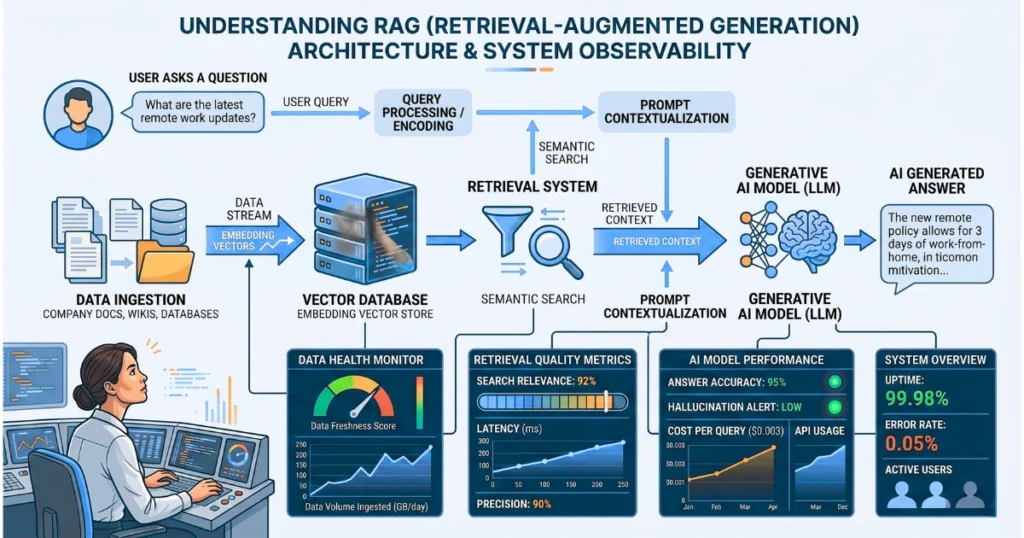
Retrieval-Augmented Generation (RAG) is essentially a system that connects AI models to real, up-to-date data. Instead of relying solely on memory, the AI:
- Searches your documents first.
- Finds relevant information.
- Uses that specific context to generate an answer.
Simple Analogy
- Without RAG → A student writes an exam entirely from memory.
- With RAG → That same student gets the exact textbook opened before answering.
How RAG Works (Step-by-Step)
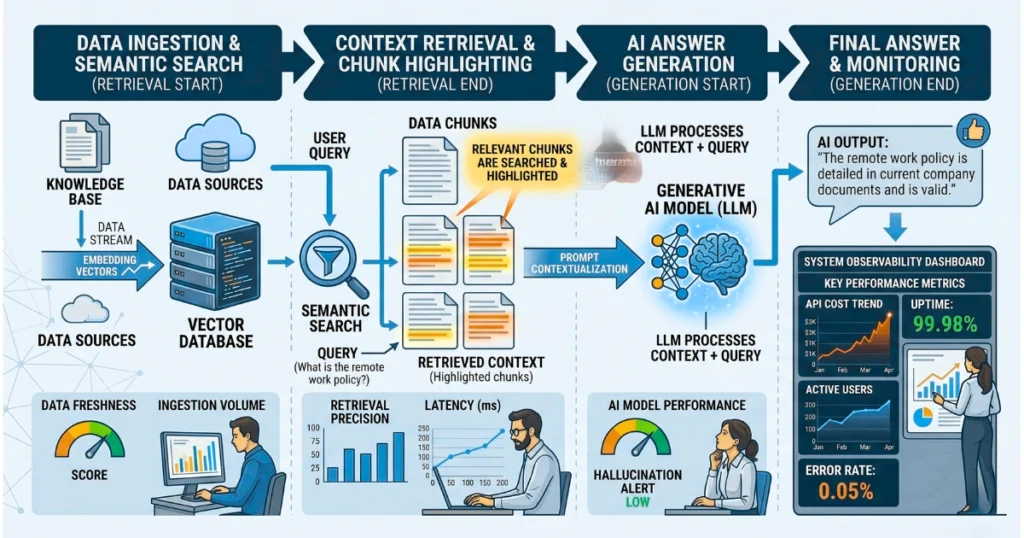
1. Retrieval Phase (Finding Relevant Data)
Initially, your documents are converted into embeddings (numerical representations). Then, when a user asks a question, the system searches for the most relevant chunks of text. Crucially, it finds matches based on semantic meaning rather than just keywords.
2. Augmented Generation Phase (Generating the Answer)
Next, the AI receives both the user’s question and the retrieved data. Afterward, it generates a response based only on that provided context, significantly reducing hallucinations.
RAG vs Fine-Tuning: What’s the Difference?
This is exactly where many developers go wrong, often making what industry veterans call the $50,000 mistake of confusing fine-tuning vs. RAG.
| Feature | RAG | Fine-Tuning |
|---|---|---|
| Purpose | Add knowledge | Change behavior |
| Data updates | Real-time | Requires retraining |
| Cost | Lower | Higher |
| Use case | Dynamic data | Tone, format |
Key Insight: Use RAG to give an AI knowledge. Conversely, use Fine-Tuning to control how it responds.
Therefore, trying to use fine-tuning for knowledge retrieval is one of the most expensive mistakes teams make.
The Modern RAG Tech Stack (2026)
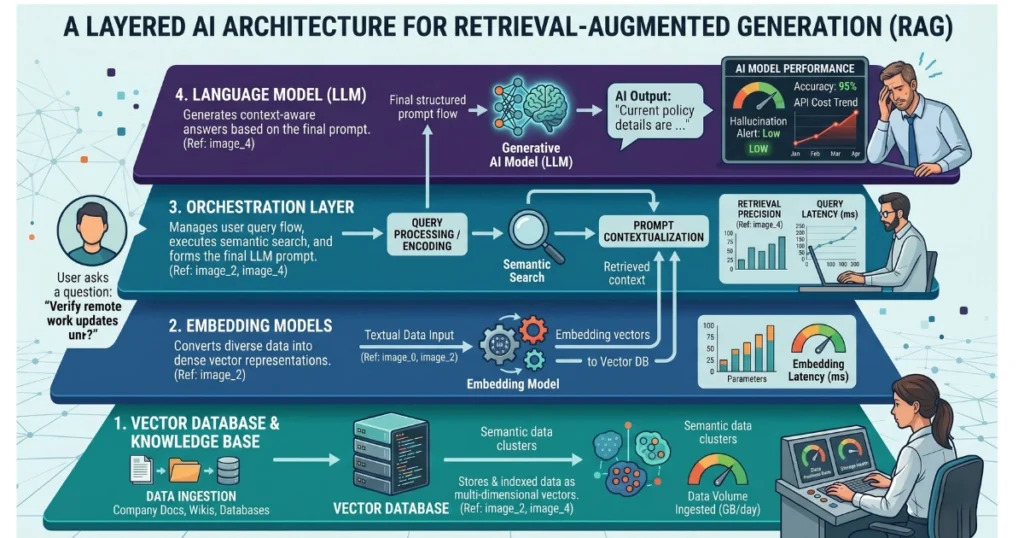
You certainly don’t need to build everything from scratch. To better understand how these layers connect, you can review our breakdown of the AI stack: models, vector databases, agents & infrastructure. Typically, a setup includes:
- Embedding Models: Convert text into vectors (e.g., OpenAI embeddings, open-source models).
- Vector Databases: Store and search data (Pinecone, Milvus, pgvector).
- Orchestration Layer: Connect everything (LangChain, LlamaIndex, or custom backend).
- LLM (Language Model): Generates final answers (GPT-4o, Claude, etc.).
Real-World RAG Examples
1. Internal HR Assistants As workflows transition from chatbots to agents that do the work for you, employees can simply ask about parental leave. Instantly, the system pulls the exact policy document and answers accurately.
2. E-commerce Support Similarly, users can ask if a product is available in size 10. In response, the system checks live inventory to provide an immediate update.
3. Legal & Financial Analysis Furthermore, professionals can query contracts, SEC filings, and large reports. By retrieving only relevant sections, RAG saves hours of manual work.
Common RAG Mistakes (That Break Your System)
1. Poor Data Chunking Splitting text incorrectly breaks context and causes wrong answers. Thus, always chunk logically by paragraph or section.
2. Ignoring Hybrid Search Vector search alone is rarely enough. Additionally, you need keyword search for exact matches and semantic search for broader meaning.
3. Outdated Data (Silent Killer) If your database isn’t updated, the AI gives outdated answers, and users lose trust instantly. Consequently, you must sync your data automatically.
How to Start Building Your First RAG App
Don’t overcomplicate it. If you need a step-by-step roadmap, follow our 2026 prompt to production guide for building AI applications.
To begin, start small:
- Use 5–10 clean documents.
- Try a managed vector DB like Pinecone.
- Focus heavily on data quality.
Crucially, 80% of success in RAG comes from clean, well-structured data—not prompts.
Final Takeaway
RAG is undeniably the foundation of reliable AI systems.
Relying exclusively on prompts will guarantee your system fails. Moreover, treating AI like a standard database means you’ll waste money. Ultimately, ignoring data quality leads directly to garbage output.
However, if you build RAG correctly, you get:
- Accurate answers
- Lower hallucination risk
- Real-world, scalable AI systems that don’t fail in production.
FAQs
- What is RAG in AI?
RAG (Retrieval-Augmented Generation) is a technique that allows AI models to retrieve real-time data before generating responses, thereby improving accuracy and reducing hallucinations. - Is RAG better than fine-tuning?
They serve different purposes. RAG is better for dynamic and updated data, whereas fine-tuning is used to control behavior and output style. - Does RAG completely eliminate hallucinations?
No, but it significantly reduces them by grounding responses in real, verifiable data.



