

Everybody in the Valley is currently lying to your face about Retrieval-Augmented Generation.
You dumped a vector database next to your generative model and told your board you solved hallucinations. However, you are functionally relying on a stochastic parrot hot-wired to a search engine.
Generative models operate entirely on predictive token distributions rather than deterministic logical retrieval. Consequently, they will constantly generate syntactically coherent garbage when the encoder maps input text into a misleading, noisy vector space.
Traditional RAG simply feeds this statistical engine a denser prompt. It falsely equates external knowledge injection with actual logical consistency.
Your system still suffers from probabilistic overfitting. It violently clings to high-probability training sequences the exact millisecond it hits a novel query outside its training distribution.
Turning down the decoder temperature does not change the underlying mathematical reality of the architecture.
Lowering the temperature won’t save your database
For instance, last week we audited a legal-tech pipeline that trusted a low-temperature model to extract contract liability clauses.
The model encountered a non-standard PDF format. Instead of throwing an error, it hallucinated syntactically perfect but legally invalid indemnification clauses and silently committed them to the master PostgreSQL database.
It corrupted 12,000 active client records before the engineering team realized the dashboard was lying to them.
Because of this, managing continuous probability distributions requires strict mathematical intervention. This is exactly why cloud providers are aggressively pushing Automated Reasoning checks to replace lazy RAG implementations.
These systems execute hard symbolic verification. They apply formal mathematical proofs to force the model’s output into alignment with concrete, pre-defined constraints.
Zero hallucination is a theoretical impossibility
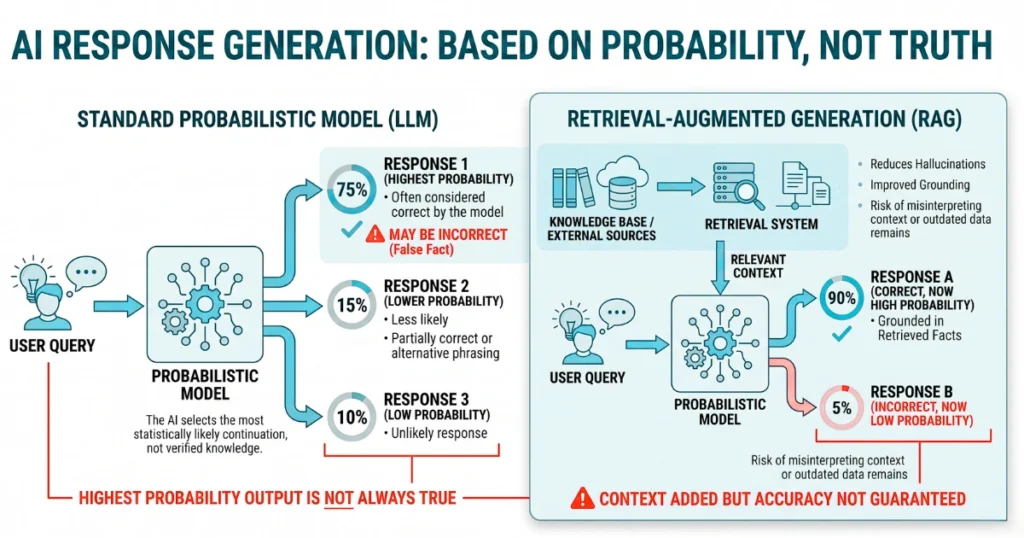
When the model inevitably fabricates a non-existent fact, real-time contextual guardrails must trap the discrepancy. Furthermore, they must execute agentic remediation, forcefully routing the broken query to a deterministic fallback script before it corrupts your downstream data.
Ultimately, you cannot extract perfect truth from an architecture built exclusively to guess the next word.
Because these systems rely entirely on continuous probability distributions and high-dimensional vector spaces, achieving absolute zero hallucination is a mathematical impossibility. Your only surviving move is to engineer a fault-tolerance layer that assumes the model will actively lie to you at scale.



