

We are lying to our compliance departments.
Indeed, engineering teams bolt RAG pipelines onto foundation models. They assume tracing the vector search step equals full system audibility. It does not.
You can log the exact document retrieved from your Pinecone instance.
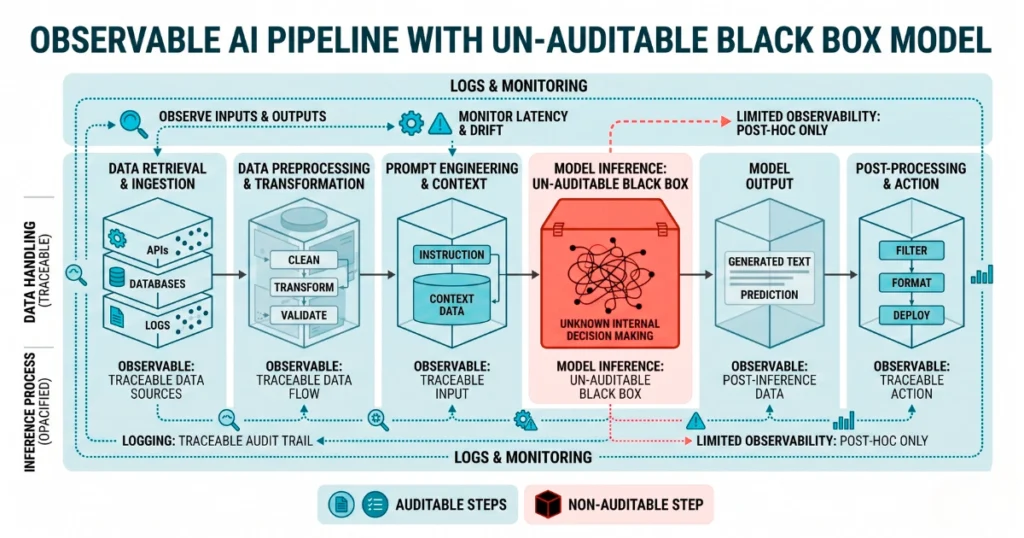
You can map the exact prompt sent to Anthropic or OpenAI. However, you still cannot mathematically prove this process. The model weights a specific token sequence over another during generation without explanation.
The Explainable AI (XAI) industry has spent three years trying to solve this. Applying secondary models to analyze primary foundation models fails. It simply creates a second, smaller black box layered on top.
Consequently, an orchestrated agent might hallucinate a synthetic legal precedent. It then injects this error into an AEO pipeline. Your observability dashboard will just show a successful API call.
Vendor abstractions actively fight auditability
AWS Bedrock presents foundation models as a simple dropdown menu. The underlying infrastructure, however, aggressively obscures the routing. AWS forces you to purchase Provisioned Throughput to customize an internal model.
For instance, last quarter we audited a healthcare provider. They completely lost track of a fine-tuned model’s lineage. A junior engineer successfully fine-tuned a model on raw patient diagnostics. Next, they executed the throughput request.
They accidentally mapped the returned ARN to the public-facing triage bot.
As a result, the bot leaked restricted HIPAA data for three weeks.
The compliance team couldn’t legally prove which base model caused the leak. The AWS dashboard buried the logs under generic inference compute. The vendor mapped the billing tag to the obfuscated endpoint instead of a readable base model ID.
You cannot audit a system when the vendor treats the model identity as a dynamic variable.
Regulators demand transparency frameworks that do not exist
The EU AI Act risk classification makes dangerous assumptions. It assumes you can track data provenance through the model’s entire lifecycle.
Your legal team might ask for an exact decision tree regarding a data leak. Handing them an AWS CloudWatch log will not hold up in court.
Therefore, true verification requires verifiable AI architectures. You must generate cryptographic proofs alongside the model’s output. These proofs mathematically guarantee the system applied a specific model to your dataset.
Ultimately, very few enterprise deployments build this level of zero-knowledge infrastructure into their LLMOps. We are building high-stakes, autonomous systems on top of probabilistic math that we cannot inspect.



