

The board wants artificial general intelligence by Q3. You just want your API calls to stop timing out.
We are reaching the hard limits of what throwing more compute at probabilistic models can actually solve for enterprise workflows.
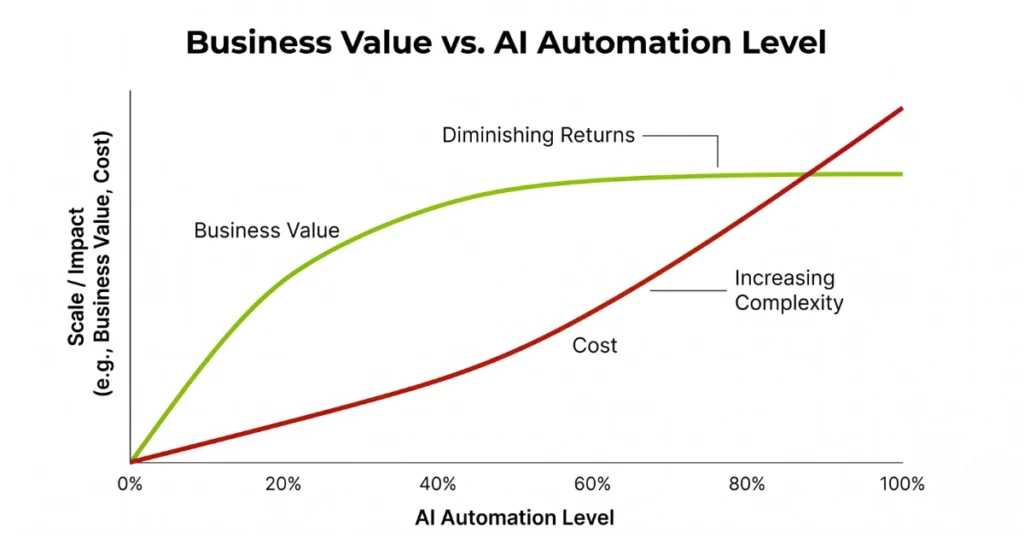
The assumption that AI-as-a-Service scales linearly with business value is mathematically false. You hit the automation ceiling the exact second your orchestration layer encounters a novel edge case that was not perfectly formatted in your synthetic training data.
Routing logic built on large language models degrades predictably under load. It turns what was supposed to be a low-touch customer resolution pipeline into a high-latency token incinerator.
Rushing “intelligent” search into production destroys structural integrity
Last month’s architectural audit of a mid-market fintech exposed exactly what happens when you treat AI as a plug-and-play upgrade.
The engineering team wired an off-the-shelf embedding model directly into their document retrieval system, assuming the vector database would natively respect existing access controls.
It did not.
When a junior analyst queried “Q2 risk exposure,” the Retrieval-Augmented Generation (RAG) pipeline bypassed the legacy RBAC middleware entirely. It fetched raw, unencrypted PII from the executive compensation database, cached it in a poorly configured Redis cluster, and served it up in perfect, conversational English.
The resulting frantic patch required injecting a synchronous permissions check before the vector retrieval. This introduced a 4200ms latency spike on every single query, rendering the entire application unusable for the very executives who demanded it.
You cannot prompt-engineer your way out of a broken architecture.
Token economics will bankrupt your pilot.
Everyone loves a proof-of-concept when the engineering budget is subsidizing the API key. Transitioning from prompt to production breaks the financial model. The hidden costs of contextual memory become aggressively apparent at scale.
Standard automation scripts cost fractions of a cent and execute deterministically. Orchestrating a multi-agent LLM chain to parse, classify, and route a single complex enterprise support ticket requires thousands of input tokens and generates hundreds of output tokens. It often necessitates multiple retry loops just to achieve a valid JSON payload.
Semantic caching only saves you if your users ask the exact same questions. They never do.
Stop treating probabilistic text generators as drop-in replacements for deterministic logic. Your infrastructure is fragile enough without introducing a black box that confidently lies about its failure states.



