Exploring AI, One Insight at a Time


How to Reduce AI API Costs: Real Strategies That Actually Work (2026)
I learned this one the expensive way.
We shipped a research agent that summarized dense technical PDFs. It worked beautifully in testing—fast, accurate, even a bit impressive. Then we pushed it live. By Monday morning, the bill was sitting at $3,800.
A small logic bug caused the agent to repeatedly send the same large document chunks to a premium model… over and over… just to produce short summaries. No safeguards, no caching, no limits.
That’s when it clicked: AI costs don’t scale linearly. They explode.
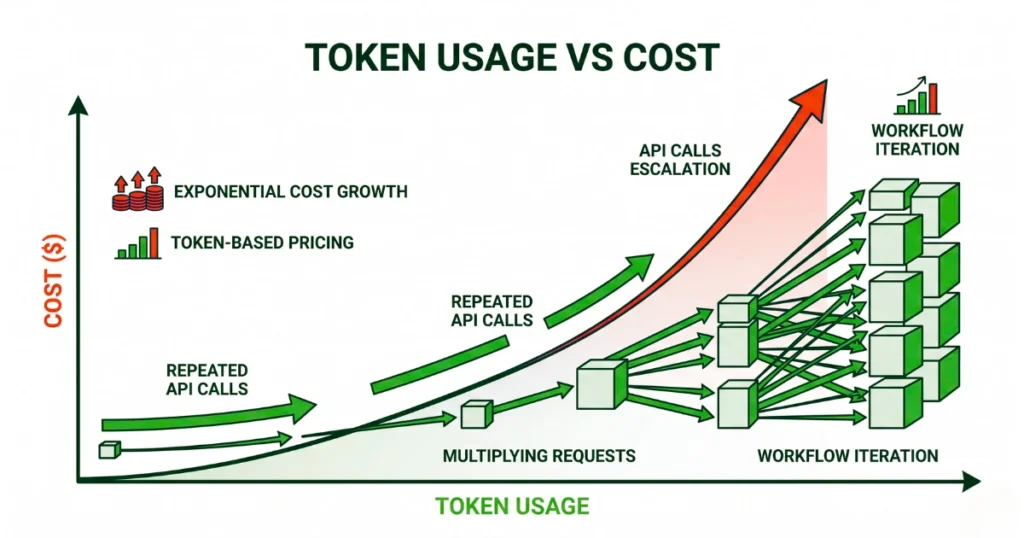
If you’re serious about building AI products in 2026, reducing API costs isn’t optimization—it’s survival.
The Core Problem: LLMs Are Not Databases
A lot of cost issues come from one wrong assumption: “Just send more context, the model will figure it out.”
That works in a demo. In production, it’s financial self-sabotage. Every extra token increase latency, reduces output quality, and quietly drains your budget.
The goal isn’t to give the model more. The goal is to give it only what it absolutely needs.
Where Most Apps Waste Money (Without Realizing It)
Before fixing anything, understand where the leaks happen:
- Recomputing identical answers for similar queries
- Sending bloated prompts (unused instructions, repeated context)
- Using premium models for trivial tasks
- Overloading RAG pipelines with irrelevant data
- Letting agents loop without limits
Fix these, and you’ll cut costs faster than any “model switch.”
1. Semantic Caching: The Easiest 30% Cost Reduction
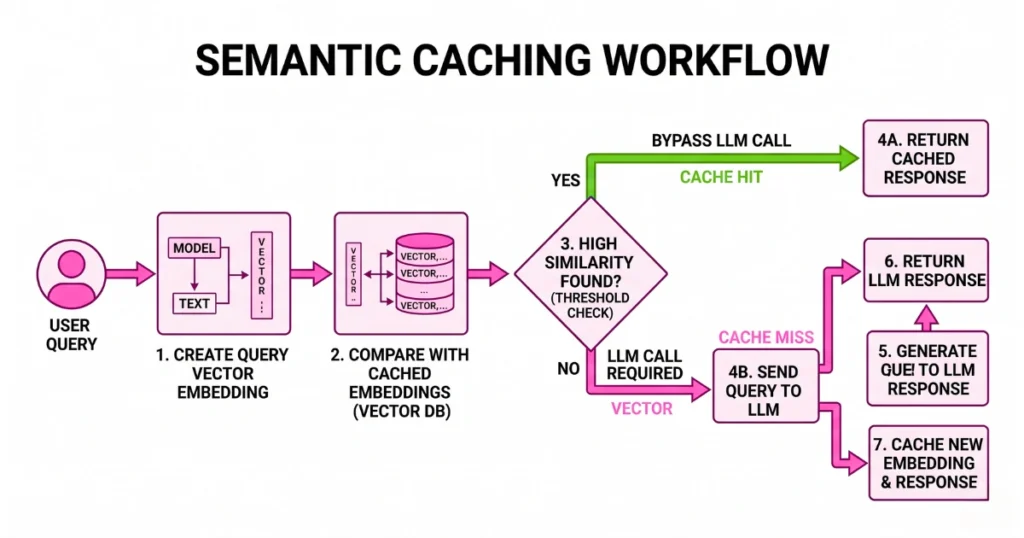
Traditional caching doesn’t work well with AI. Users don’t ask the same question twice—they rephrase it. That’s where semantic caching comes in. Instead of matching exact strings, you match meaning.
How it works (in practice):
- Convert the incoming query into an embedding.
- Compare it against stored embeddings.
- If similarity is high (e.g., > 0.9), return the cached answer.
- Skip the LLM entirely.
Why this matters: Zero token cost for repeated questions, instant responses (no model latency), and massive savings at scale. In real systems, this alone can eliminate 20–40% of API calls.
2. Prompt Compression: Stop Paying for Garbage Tokens
Most production prompts are messy. They include redundant instructions, unused fields, repeated system messages, and unnecessary formatting. And every single character costs money.
Simple fixes:
- Strip whitespace and unused fields.
- Deduplicate repeated instructions.
- Shorten system prompts aggressively.
- Remove debug metadata before sending.
It’s not glamorous, but trimming prompts can reduce token usage by 15–25% instantly.
3. Fix Your RAG Pipeline (This Is Where Money Disappears)
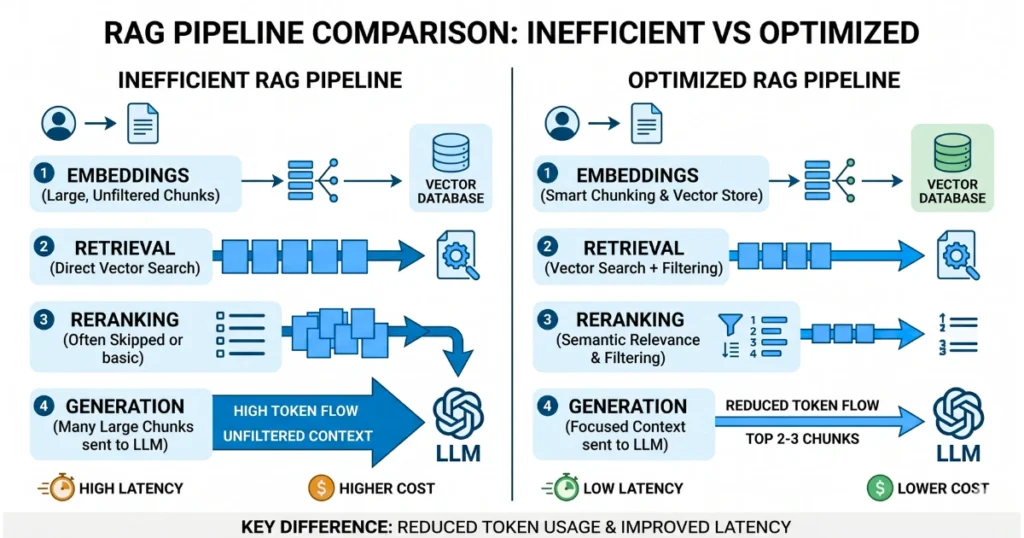
RAG is powerful—but badly implemented RAG is a cost nightmare.
The biggest mistake: Sending too much context. If your system retrieves large chunks (1000–2000 tokens each), you’re forcing the model to read a novel just to answer a simple question.
What actually works:
- Retrieve more candidates.
- Send only the top 2–3 ranked chunks.
- Keep chunks small and clean (200–500 tokens).
Push computation to cheaper layers: embeddings (cheap) → vector search (cheap) → re-ranking (cheap) → generation (expensive). Use the cheap layers to filter aggressively.
4. Dynamic Model Routing: Stop Using a Ferrari for Everything
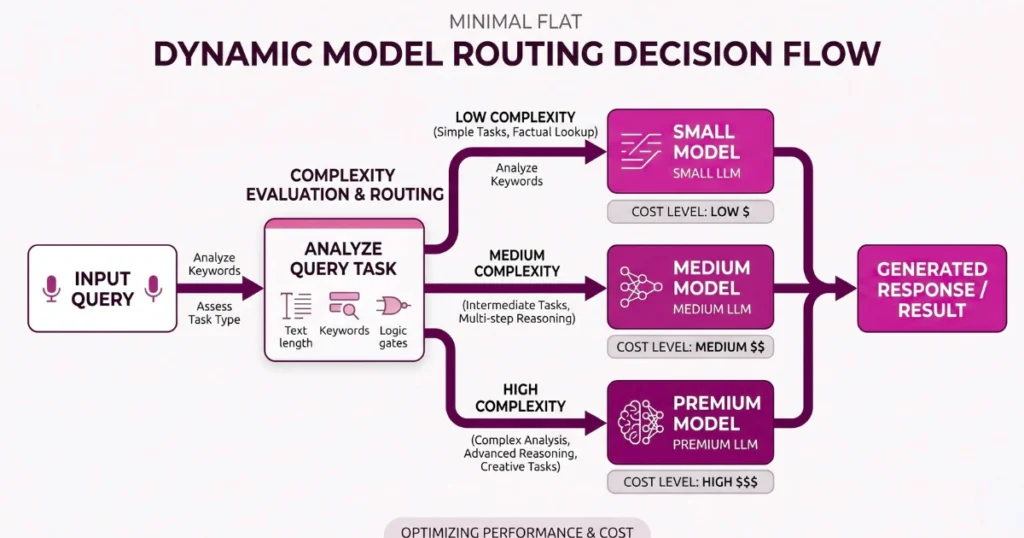
This is where most teams burn money. Not every request needs a high-end model.
Real-world breakdown:
| Task | Model Type |
|---|---|
| Classification / tagging | Small, cheap model |
| Basic summaries | Mid-tier model |
| Complex reasoning | Premium model |
The idea: Build a routing layer that decides: “Is this query simple or complex?” and “What’s the cheapest model that can handle it?” Even a basic routing system can cut costs by 50% or more.
5. Control Agent Behavior (Before It Controls Your Wallet)
Agents are powerful—but dangerous. They retry automatically, loop on failure, and generate intermediate steps. Which means… they silently multiply your API usage.
Non-negotiable safeguards:
- Max iteration limits (e.g., 3–5 loops)
- Timeout controls
- Cost caps per request
- Clear failure exits
If you don’t control this, one bug can drain your budget overnight.
6. Batch Processing for Background Tasks
A common mistake is using real-time APIs for everything. Not all tasks need instant responses. Examples include log analysis, document indexing, and report generation. These should run asynchronously using batch APIs.
Why: Lower pricing (often ~50% cheaper), no need for low latency, and much better resource efficiency.
7. Set Hard Limits (Or Pay for It Later)
This is boring—but critical. Without limits, your AI feature becomes an open invitation for abuse.
You need:
- Per-user token quotas
- Rate limiting
- Request size limits
- Input validation
Otherwise, bots will spam your endpoints, users will unintentionally overload your system, and costs will spiral without warning.
8. Monitor Everything (Not Optional)
You can’t optimize what you don’t track.
Minimum tracking setup:
- Tokens per request
- Cost per feature
- Cost per user
- Model usage distribution
Once you see where the money is going, optimization becomes obvious.
The Real Mindset Shift
Reducing AI costs isn’t about finding a cheaper model. It’s about designing a smarter system around the model. The best teams minimize unnecessary generation, shift work to cheaper layers, reuse results aggressively, and control execution paths.
The model is just one component. The architecture is where your margins live.
Final Takeaway
If your AI app is getting expensive, the issue usually isn’t the model. It’s how you’re using it.
Start with this: add semantic caching, reduce prompt size, limit RAG context, route intelligently, and cap agent loops. Do just these five things, and your costs won’t just drop—they’ll stabilize. And in 2026, predictable AI costs are a competitive advantage.
FAQs
- What’s the fastest way to reduce AI API costs?
Implement semantic caching and dynamic model routing. These two changes alone can drastically reduce unnecessary API calls. - Do bigger context windows increase cost?
Yes. Larger context means more tokens processed, which directly increases cost and often reduces accuracy. - Should I always use cheaper models?
No. Use cheaper models for simple tasks, and reserve premium models for complex reasoning where they actually add value. - How do I prevent runaway API bills?
Set strict limits: iteration caps, request quotas, and timeout rules. Never allow open-ended loops in production systems.



