
If you are looking up how to build an AI app from scratch in 2026, you have likely already drowned in a sea of overly optimistic documentation. The generative AI landscape has matured, but the tutorials are still lying to you.
The gap between a basic “Hello World” API wrapper and a production-grade, streaming AI application is paved with hidden hardware bottlenecks, framework bloat, and serverless crashes.
In 2026, building a resilient AI stack means stripping away the magic and taking absolute control over your raw byte-stream.
Here is the unvarnished, step-by-step guide to building an AI app that actually survives production.
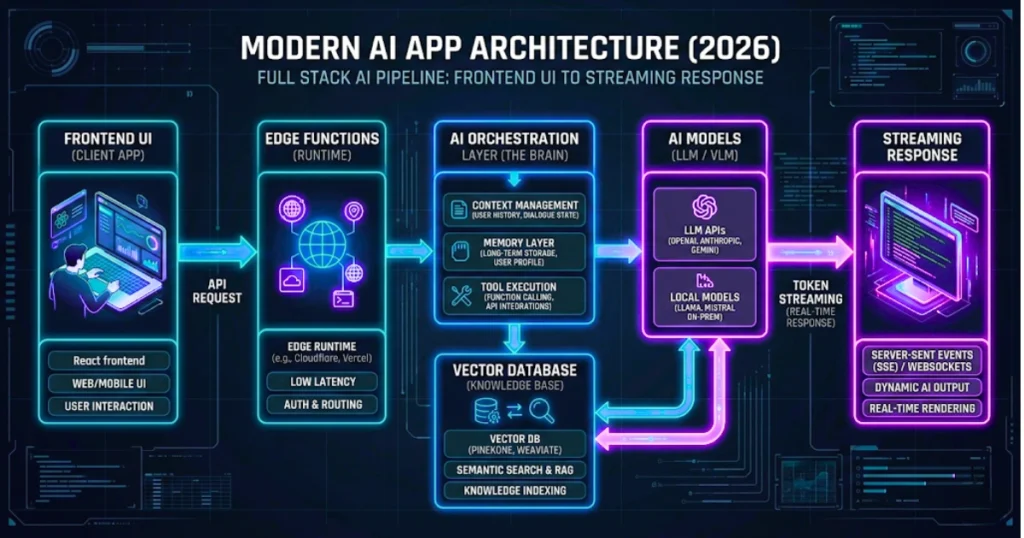
Step 1: Architecting Your Inference (The Local Hardware Trap)
The first decision in any AI build is where your model lives. If you are leaning toward local LLM deployment to save costs or protect data, beware: local inference hardware is a lie of omission.
Local deployment on consumer silicon is a battle against mathematical optimism. You might think running a 70B model with 4-bit quantization on an RTX 4090 is perfectly fine because the documentation suggests 24GB of VRAM is sufficient. It is not.
The moment you start generating long-context outputs, K/V cache expansion will destroy your memory overhead.
Hidden context settings in tools like llama.cpp on Windows trigger immediate CUDA Out of Memory (OOM) errors.
The 2026 Fix:
- Calculate your overhead: Manually calculate the memory footprint of your context window before allocating tensor layers to the GPU.
- Clamp aggressively: Production-grade local stacks require aggressive context clamping. If you do not explicitly manage this, the kernel will panic mid-request.
Step 2: Designing the Network Layer (Beating Serverless Timeouts)
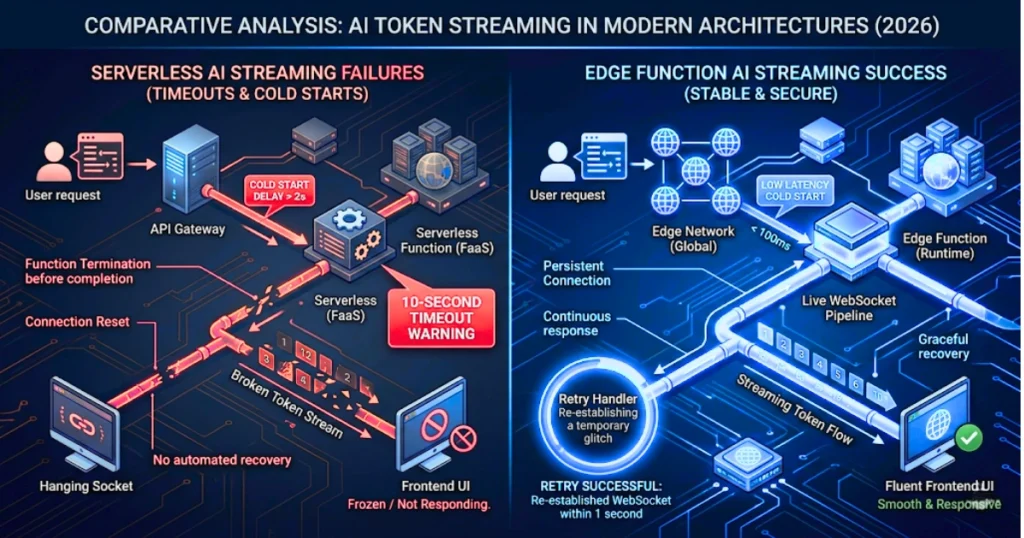
Localhost development creates a dangerous illusion of architectural stability. Once you push to the cloud, serverless timeouts will kill your production stream.
If you are using standard Vercel serverless functions, you are fighting a default 10-second execution ceiling. This creates a hard, fatal disconnect while you wait for the OpenAI API (or your local equivalent) to return its first token.
Furthermore, the official OpenAI React SDK lacks robust handling for these ungraceful disconnects, leaving your frontend hanging indefinitely in a frozen “loading” state.
The 2026 Fix:
- Migrate to Edge: Shift all inference calls to Edge Functions to bypass cold starts and traditional execution limits.
- Manage the Delta: Implement manual client-side timeout handlers. Reliability today is measured entirely by your ability to manage the delta between a hanging socket and a live stream.
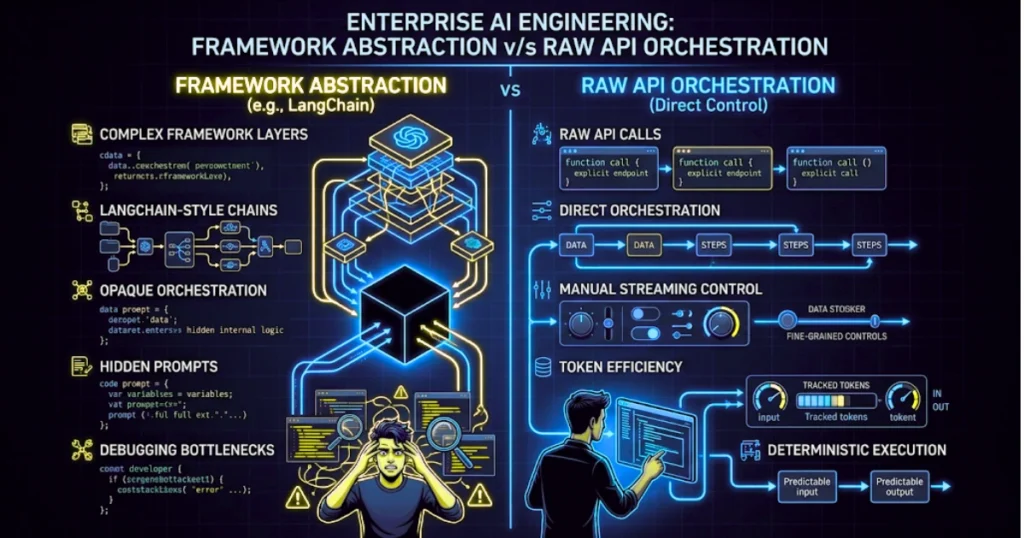
Step 3: Choosing the Orchestration Logic (Ditch the Abstractions)
In 2024, everyone used wrapper frameworks. In 2026, we know better: abstracted frameworks are the primary debugging bottleneck.
Frameworks like LangChain create a black box. They wrap your logic in fifteen class layers that completely obscure the underlying system prompt. Developers are losing weeks troubleshooting one-sentence logic failures buried inside opaque “Chain” abstractions.
The 2026 Fix:
- Write raw API calls: A raw Python while loop achieves the exact same orchestration result in twenty lines of code that you can actually read.
- Own your byte-stream: Senior architects are reverting to direct API calls to regain control over token efficiency and orchestration costs. Custom logic outperforms framework abstractions because it allows for granular control over hallucination mitigation and context injection.
Step 4: Building the Frontend (Taming React Streaming UI)
Streaming text to a frontend is the standard UX for AI apps, but React Strict Mode is fundamentally destructive to streaming UI.
Stateful streaming in modern React components simply does not play well with standard mounting lifecycles. During development, React Strict Mode double-fires the streaming hook.
This instantly scrambles incoming text chunks and duplicates rendered words directly in your chat interface. Additionally, standard state updates will consistently lag behind a rapid token payload, causing severe visual stuttering and context desynchronization.
The 2026 Fix:
- Avoid default hooks: Relying on default framework hooks fails entirely under the stress of high-frequency token generation.
- Use isolated state: Managing the delta between the raw string buffer and the React virtual DOM requires implementing manual debouncing and using isolated state refs (
useRef) to track the token stream without triggering endless re-renders.
Step 5: Structuring the Output (The JSON Mode Myth)
Your application needs structured data to function, but native JSON Mode is marketing, not a data guarantee.
You might assume that setting response_format= {"type": "json_object"} makes your app bulletproof.
It doesn’t. GPT-4o (and similar models) will still betray your schema and crash your application parser with markdown pollution. The model frequently wraps the output in markdown triple-backticks. This metadata contamination causes standard JSON.parse() calls to throw fatal exceptions in production.
The 2026 Fix:
- Assume contamination: You cannot trust an LLM to return a clean object without an intermediate utility layer.
- Regex is your friend: Build a strict regex-based sanitization layer that strips the
```jsonprefix and suffix before parsing. Validating your output schema requires this secondary guardrail to prevent your frontend from consuming malformed strings.
The Bottom Line for AI Engineering in 2026
Learning how to build an AI app from scratch in 2026 means unlearning the “magic” sold by API providers. The modern AI tech stack isn’t built on high-level, bloated abstractions.
It is built on regex sanitizers, Edge-runtime listeners, strict manual context management, and raw API calls. Master the bare metal of your request stream, and your app will outlast the competition.



