

Let’s be real: Retrieval-Augmented Generation (RAG) isn’t just a buzzword anymore; it’s the absolute backbone of modern AI. Whether you’re building a simple customer service chatbot or a massive enterprise brain, your app lives and dies by how fast and accurately it can fetch context.
Picking a vector database isn’t just checking a box on your backend to-do list. It messes directly with your latency, your cloud bill, and how smart your AI actually sounds to the end-user. Because these databases sit right at the bottom of your core AI stack, we need to look past the marketing fluff.
Here’s a raw look at the best vector databases for RAG in 2026, focusing heavily on the engineering headaches you’ll actually face in production.
Why Postgres + pgvector Isn’t the Magic Bullet
A lot of dev teams immediately slap pgvector onto their existing Postgres setup. And I get it—nobody wants to manage another database. Keeping it all under one roof feels clean and keeps the DevOps team happy.
Sure, if you throw in extensions like pgvectorscale or DiskANN, Postgres looks like an absolute beast in benchmarks, effortlessly handling millions of vectors. But wait until you actually push it to production. That’s when building scalable AI systems gets tricky.
The ORM Headache
You’re probably using Prisma or something similar, right? The problem is that modern ORMs still completely drop the ball on native vector support. You end up having to write raw SQL just to get anything done.
JavaScript
// Prisma lacks native vector support → raw SQL workaround
const results = await prisma.$queryRaw`
SELECT id, content, 1 - (embedding <=> ${vector}::vector) AS similarity
FROM "Document"
WHERE "tenantId" = ${tenantId}
ORDER BY embedding <=> ${vector}::vector
LIMIT ${limit};
`;
Writing code like this completely wrecks your type safety. It’s a massive pain to maintain and makes scaling your codebase a nightmare as the app grows.
The Hybrid Search Mess
Pure vector search is great until a user searches for a highly specific term. RAG requires hybrid retrieval—mixing semantic meaning with exact keyword matches. Postgres doesn’t do this out of the box. You’ve got to duct-tape tsvector for the text stuff and HNSW for the vectors.
The result?
- A fragmented, clunky query pipeline
- Endless tuning just to get the relevance right
- Nasty latency spikes when traffic hits
When Dense Retrieval Fails
Semantic similarity completely falls on its face with specific alphanumerics. Try searching for an error code like ERR_CODE_0x4F9, a product SKU, or a weird drug name using pure dense embeddings. It just doesn’t work. Dense vectors aren’t built for exact matches.
Why Hybrid Search is Non-Negotiable
If you want your RAG system to actually work in the wild, you have to fuse BM25 (good old-fashioned lexical search) with your vector search. Here’s how the big players handle that fusion.
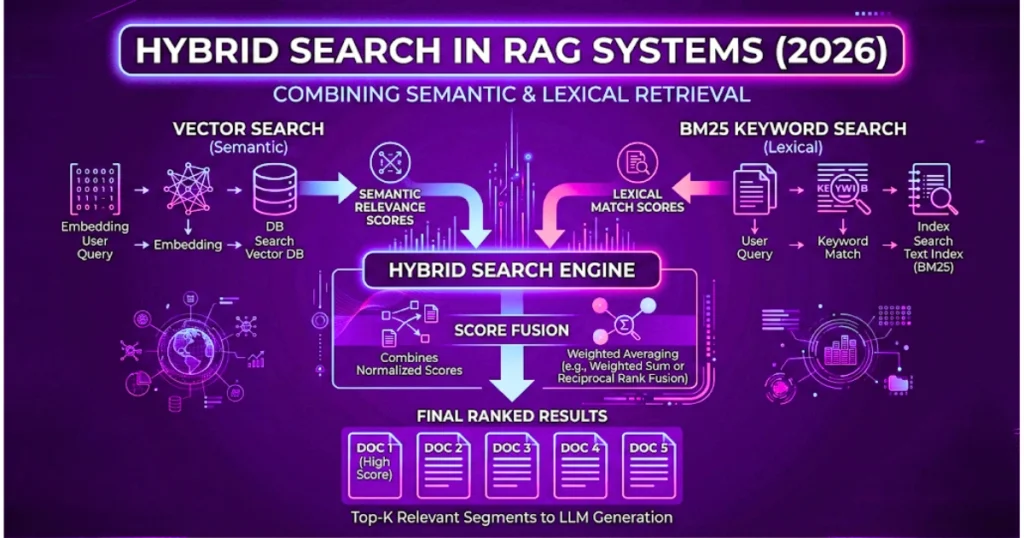
Weaviate: The Built-In Option
Weaviate is pretty sweet because it bakes hybrid search right in. You don’t need a crazy separate infrastructure setup to make it work.
Python
import weaviate
client = weaviate.connect_to_local()
collection = client.collections.get("Documentation")
response = collection.query.hybrid(
query="ERR_CODE_0x4F9",
vector=embedding_vector,
alpha=0.5,
limit=5
)
It literally handles the score fusion for you behind the scenes. Zero fuss.
Vespa: The Heavyweight
Vespa is an absolute powerhouse. It handles massive indexes and lets you tweak ranking expressions to your heart’s content. It even supports late-interaction models like ColBERT.
But man, the learning curve is brutal. It requires incredibly complex schema design. You’re going to spend a lot of engineering hours just getting it off the ground.
What Happens When You Actually Scale?
Tools that feel snappy and responsive on your local machine often choke when you cross the 10-million vector mark. As your system grows, scaling constraints slap you in the face—especially in multi-tenant environments.
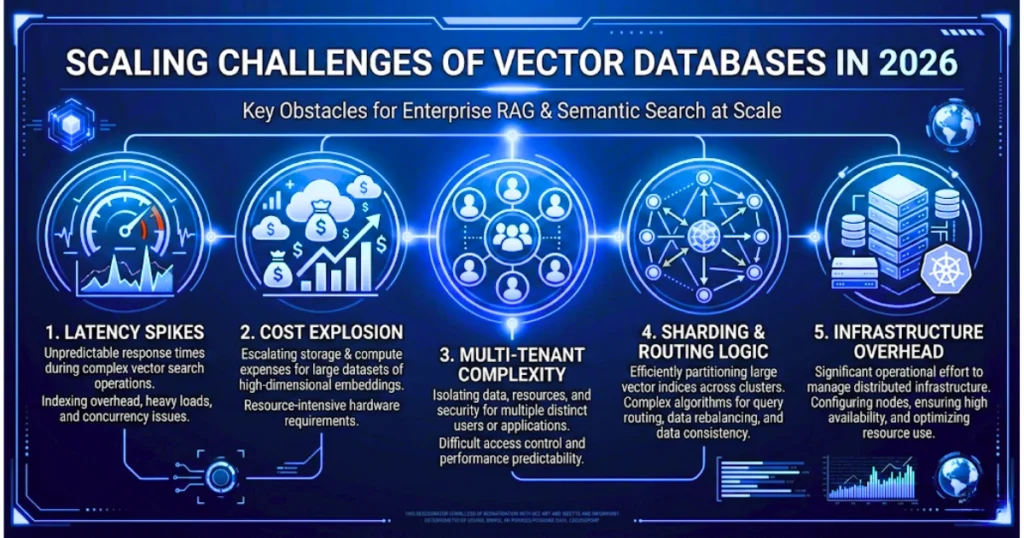
Pinecone: Quick but Pricey
Pinecone’s serverless setup is a dream for getting an MVP out the door. You separate compute and storage, get great latency, and skip the DevOps headache entirely.
But watch out. If you aren’t actively trying to reduce AI API and infrastructure costs, your usage bills will skyrocket as query volume goes up. Plus, they cap you at 100K namespaces. If you’re running a massive multi-tenant app, you’ll inevitably end up writing custom sharding logic just to bypass their limits:
Python
def get_pinecone_namespace(tenant_id: str, client_count: int) -> str:
shard_id = hash(tenant_id) % 10
return f"shard_{shard_id}_{tenant_id}"
Suddenly, you’re managing routing complexity anyway.
Milvus: The Big Data Beast
If you’re dealing with hundreds of millions of vectors, Milvus is usually where you end up. It’s built from the ground up for insane throughput and distributed workloads.
The catch? You better know Kubernetes. It requires managing etcd, Kafka, and the cluster itself. You’re basically trading a high monthly SaaS bill for serious operational heavy lifting.
Don’t Forget Your Chunking Strategy
Before you even worry about which database to use, look at your data. How you slice up and structure your text chunks makes or breaks your retrieval quality.
Bad chunking guarantees garbage results, terrible recall, and way more hallucinations in generated responses. Even a multi-million-dollar vector database can’t save poorly formatted input data.
The 2026 Vector Database Cheat Sheet
To wrap this up, here is a quick breakdown of which tool fits your specific stack:
| Use Case | Recommended Database | The Real Advantage |
|---|---|---|
| Fast MVP deployment | Pinecone | Pure serverless, zero DevOps to start |
| Existing SQL-based stack | pgvector | Easy to just bolt onto Postgres |
| Built-in hybrid search | Weaviate | Fuses BM25 + vectors effortlessly |
| Massive scale (100M+) | Milvus | Handles insane throughput natively |
| Control freaks | Vespa | Unmatched ranking customization |



