

For years, artificial intelligence worked in silos. One model processed text. Another analyzed images. A separate system handled audio or video.
But in 2026, AI is becoming something far more powerful: Multimodal AI.
Instead of understanding only one type of input, modern AI systems can now process:
- text
- images
- audio
- video
- live environments
- contextual signals
…all at the same time.
This shift is fundamentally changing how humans interact with machines. AI is no longer just reading prompts or recognizing pictures. It’s beginning to understand context more like humans do — by combining multiple forms of information simultaneously.
And that changes everything from customer support and content creation to security, healthcare, education, and enterprise automation.
What Is Multimodal AI?
Multimodal AI refers to artificial intelligence systems capable of processing and combining multiple types of data together.
In machine learning, a “modality” simply means a type of information.
Examples include:
- text
- images
- speech
- video
- sensor data
- facial expressions
- movement
Traditional AI systems usually operate on a single modality.
For example:
- Chatbots process text
- Image recognition models analyze photos
- Speech assistants interpret voice
Multimodal AI merges these capabilities into a unified system. Instead of analyzing inputs separately, the model understands relationships between them.
Example: A multimodal AI assistant can:
- analyze an uploaded image
- understand spoken instructions
- recognize emotional tone
- generate contextual responses
- create visual or written outputs
…all within a single interaction.
Why Multimodal AI Is Becoming So Important
Human communication is naturally multimodal. We don’t rely on text alone. We combine tone of voice, facial expressions, visuals, gestures, context, and language to understand meaning.
Multimodal AI brings machines closer to that kind of contextual understanding. This is why companies are aggressively investing in multimodal systems across customer service, retail, healthcare, autonomous systems, education, security, and enterprise operations.
The goal is simple: Make AI interactions feel more natural, responsive, and context-aware.
The Evolution of Multimodal AI
The modern wave of multimodal AI accelerated rapidly after the release of advanced large models capable of handling both text and visual inputs effectively. Earlier AI systems specialized in narrow tasks. But newer architectures can now:
- understand images and text together
- process live audio conversations
- analyze video streams
- generate content across multiple formats
This evolution is pushing AI beyond simple chat interfaces into fully interactive digital systems. In 2026, multimodality is becoming one of the defining trends in artificial intelligence.
Multimodal AI vs. Traditional AI
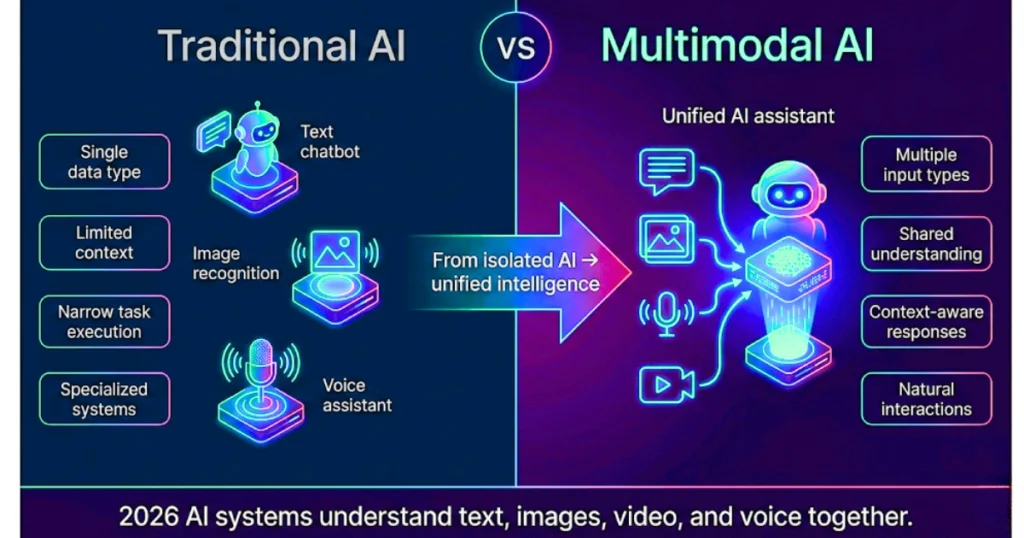
Traditional (Unimodal) AI
Processes only one type of data.
Examples:
- text-only chatbots
- image classifiers
- speech recognition systems
These systems are highly specialized but limited in contextual understanding.
Multimodal AI
Processes multiple data types simultaneously.
Example: An AI system could watch a video, listen to speech, read subtitles, analyze emotions, and summarize the entire interaction. This creates richer understanding and more intelligent responses.
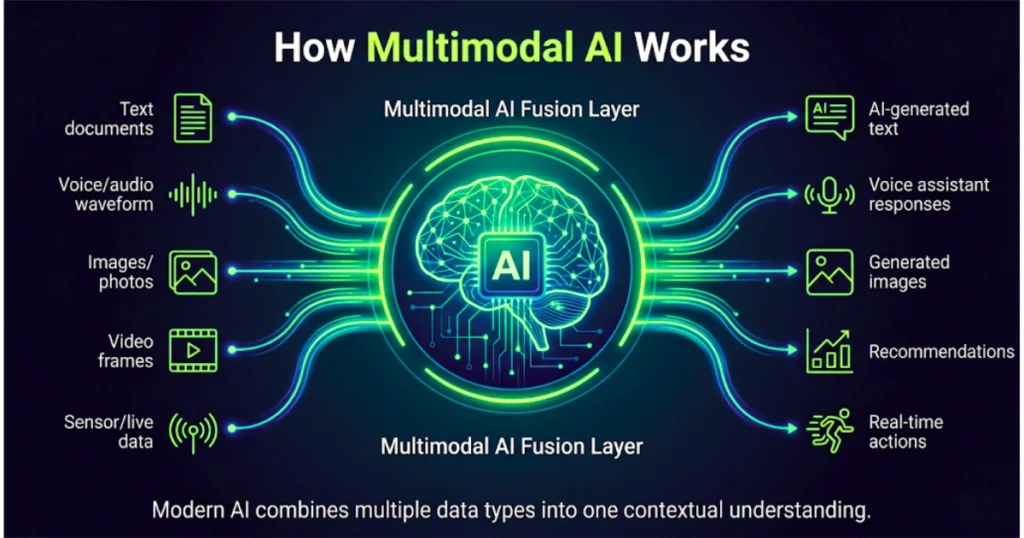
How Multimodal AI Actually Works
Although implementations vary, most multimodal AI systems follow a similar structure:
1. Input Processing Layer
Different neural networks process different types of information. For example, one network handles images, another processes text, and another interprets audio. Each converts raw inputs into mathematical representations.
2. Fusion Layer
This is where multimodal intelligence happens. The system combines information from all modalities into a shared contextual understanding. Instead of viewing text, images, or audio separately, the model connects them together.
Example: If a user uploads a photo and says, “Why does this device look damaged?” The AI links visual damage patterns, spoken language, and contextual intent to generate an accurate response.
3. Output Layer
The model then generates outputs such as text responses, generated images, speech, recommendations, or actions based on the combined understanding.
The Core Idea Behind Multimodal Models
At the heart of multimodal AI is one critical concept: Different types of data can represent the same meaning.
For example:
- the word “dog”
- a photo of a dog
- the sound of barking
- a video of a running dog
…all point toward the same underlying concept. Multimodal models learn to map these different inputs into a shared semantic space. This allows AI systems to understand relationships across formats.
How Text-to-Image AI Works
One of the most popular multimodal applications is text-to-image generation. These systems use diffusion-based architectures that begin with random noise and gradually transform it into meaningful visuals.
The process works like this:
- Step 1: Text Understanding – The AI converts written prompts into mathematical embeddings representing meaning (e.g., “A futuristic city at sunset” becomes a vector representing objects, style, lighting, context).
- Step 2: Visual Mapping – The model aligns textual meaning with learned visual patterns.
- Step 3: Image Generation – The diffusion system gradually removes noise until the final image matches the prompt.
This is how modern AI image generators create highly realistic or stylized visuals from simple text instructions.
How Multimodal AI Learns
Training multimodal AI requires enormous datasets containing connected information. Examples include image + caption pairs, video + subtitles, speech + transcription, and audio + emotion labels.
The model learns by aligning related concepts together. If an image and text represent the same idea, their internal representations are pushed closer mathematically. If they are unrelated, the model separates them. Over time, the AI builds shared understanding across multiple modalities.
Beyond Text and Images: Voice, Video, and Live Context
In 2026, multimodal systems are evolving far beyond text-to-image generation.
Modern AI can increasingly understand live conversations, analyze video feeds, recognize emotional tone, interpret environmental context, and process real-time interactions. This opens the door to AI systems that behave more like intelligent assistants than isolated tools.
Real Business Applications of Multimodal AI
- Customer Support:
Multimodal AI can analyze customer messages, voice tone, screenshots, and emotional sentiment. This enables faster and more personalized support experiences. - Retail & E-Commerce:
AI shopping assistants can recognize products visually, understand voice requests, and recommend items contextually, creating more interactive shopping experiences. - Security & Surveillance:
Multimodal systems combine video analysis, audio monitoring, and behavioral detection to identify threats more accurately in real time. - Healthcare:
AI systems can combine medical scans, patient records, doctor notes, and speech interactions to improve diagnostics and clinical decision-making. - Manufacturing:
Factories increasingly use multimodal AI to monitor machinery visually, analyze sensor data, predict failures, and optimize maintenance schedules before breakdowns occur.
The Rise of Real-Time AI Assistants
One of the biggest shifts happening now is the emergence of real-time multimodal assistants. These systems can see, hear, speak, understand context, and interact naturally simultaneously.
Instead of typing prompts manually, users increasingly interact with AI conversationally using multiple input types at once. This is pushing AI closer toward becoming an always-available digital partner.
The Risks of Multimodal AI
As powerful as multimodal AI is, it also introduces serious risks:
Deepfakes & Synthetic Media
AI-generated audio and video are becoming increasingly realistic. This raises concerns around misinformation, impersonation, fraud, and political manipulation.
Privacy Concerns
Multimodal systems often process highly sensitive personal data including voice, facial expressions, behavior, and location context. Strong governance and safeguards are essential to prevent abuse and data leaks.
Bias & Misinterpretation
If training data contains bias, multimodal systems can amplify unfair or harmful outcomes across multiple channels simultaneously.
Overdependence on AI
As systems become more capable, humans may increasingly rely on AI-driven decision-making for daily tasks and strategic choices.
The Bigger Shift: AI Is Becoming Context-Aware
The most important change isn’t just that AI can process more data types. It’s that AI is beginning to understand context.
That moves artificial intelligence from reactive systems → toward adaptive intelligence.
Multimodal AI allows machines to interpret situations more holistically instead of processing isolated commands. And that’s what makes this transition so significant.
Closing Perspective: The Interface Is Disappearing
For decades, humans adapted to computers. We learned interfaces, commands, menus, and workflows.
Multimodal AI reverses that relationship. Now, AI is learning how humans naturally communicate: visually, verbally, emotionally, and contextually.
The result is a future where interacting with AI feels less like operating software… and more like communicating with intelligence itself.



