

I didn’t have a dramatic “this changes everything” moment with AI. It was more subtle than that.
Back in 2018, I saw a model generate a paragraph that was… decent. Not great. A bit off in places. But a few lines felt natural enough that I paused and reread them. That was new.
What stuck with me wasn’t that it was good. It was that it was close.
Since then, I’ve spent a lot of time working around these systems. Enough to stop thinking of them as mysterious. If anything, they’re the opposite—very mechanical once you break them down.
The Mechanics of Prediction
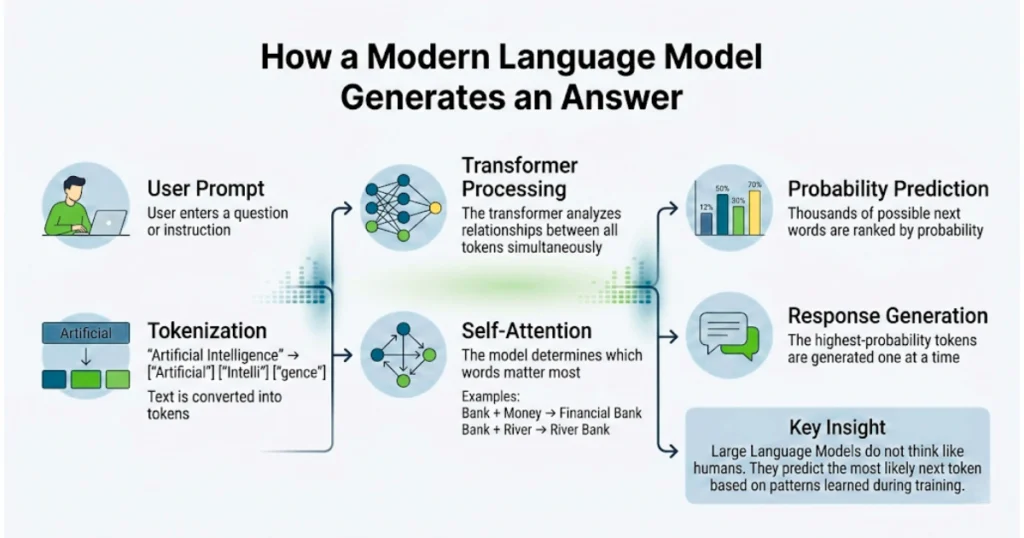
At a basic level, a language model just tries to continue text. That’s really it. You give it a sentence, and it tries to guess what comes next. Then it repeats that process over and over until you get something that looks like a paragraph.
It sounds underwhelming when you say it like that. But the scale is what makes it work.
When you type something in, the model doesn’t “read” it the way we do. It slices the text into tokens—sometimes whole words, sometimes fragments—and converts those into numbers. From there, everything is handled as math.
No meaning. No intent. Just numbers moving through layers.
Enter the Transformer
The part that made this approach actually useful was the shift to transformers. Before transformers, models handled text in order, one word at a time. That created problems. Long sentences would lose context, and anything complex would fall apart pretty quickly.
Transformers flipped that. Instead of going step by step, the model looks at the entire input at once.
People call this “self-attention,” which sounds more complicated than it needs to be. All it really means is the model is constantly figuring out which words matter more in relation to others. That’s how it deals with ambiguity.
- Take the word “bank.”
- If the surrounding text mentions money, the model leans one way.
- If it mentions water or a river, it leans another.
It’s not understanding the difference—it’s just seen enough examples to know which direction is more likely.
Training: Repetition and Probabilities
That pattern-learning comes from training. And there’s a lot of it.
During pre-training, the model is exposed to huge amounts of text—books, articles, forums, code. There’s no neat labeling. It just keeps trying to predict the next token and adjusts itself each time it’s wrong.
It’s repetitive. Almost boring as a process. But after enough iterations, the model starts producing language that feels coherent. Then it starts sounding fluent. Eventually, it gets to the point where people start attributing understanding to it.
That’s where things get a bit misleading. Because the model doesn’t actually know anything.
Why Models “Fail”
There’s no internal database it can reliably query. What it has instead is a massive set of probabilities shaped by training. That’s why it can give you an answer that sounds completely confident and still be off.
I’ve run into this a lot—especially when testing edge cases. Two responses can look equally solid on the surface. Same tone, same structure. One is correct, the other isn’t. If you don’t already know the topic, it’s hard to tell the difference.
That’s not the model “failing” in the usual sense. It’s just doing what it’s designed to do—continue patterns.
Scale and Real-World Use
Despite that, it’s incredibly useful. I’ve used it to sketch out drafts that would’ve taken much longer to write from scratch. Not final drafts—more like something workable. Developers use it in a similar way: quick suggestions, rough solutions, something to build on.
It speeds things up. It doesn’t replace thinking.
Scale obviously matters here. Larger models tend to handle nuance better. They keep track of context more effectively and produce smoother outputs. But bigger doesn’t really change the core behavior. It just makes the results more convincing.
That distinction matters. Because it’s easy to mistake fluency for understanding.
The Path Forward
Right now, the direction things are heading feels less like a single breakthrough and more like steady expansion. Models are branching out into images, audio, and video. There’s ongoing work on improving reasoning, though that term gets stretched quite a bit.
At the same time, there’s more interest in smaller, focused models. In many cases, a specialized system does the job better than a massive general one.
If I had to sum it up in a way that still feels accurate after all these years, it would be this:
A language model isn’t thinking.
It’s just very, very good at continuing patterns in a way that feels natural to us.
And that “feels natural” part is what makes everything else confusing.



