

I’ve spent the last three months compiling architectural research for our upcoming From Prompt to Production guide.
During a recent enterprise pilot, an autonomous router I deployed got stuck in a recursive authentication loop with a legacy CRM endpoint. The vendor’s rate-limit documentation was entirely inaccurate, and my agent blindly retried until it burned $400 in tokens over a single weekend.
That failure cemented a hard truth for our engineering team. Building reliable AI agents requires rigorous, defensive software engineering rather than just clever prompt engineering.
To survive the industry shift toward true AI-as-a-Service (AaaS), you need robust AI agent design patterns that handle the messy reality of production environments.
The Foundation Model Fallacy: AI Agent Design Patterns Over Raw Intelligence
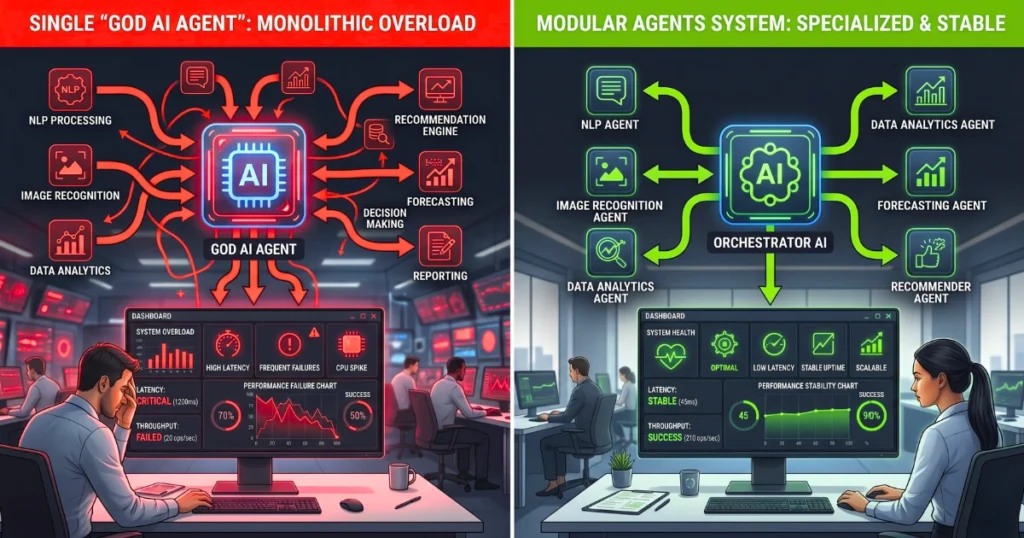
Most engineering teams assume that upgrading to the newest foundation model will inherently solve agent reliability. This is a dangerous trap. Treating your LLM as a monolithic “God brain” that handles planning, routing, and execution simultaneously leads to catastrophic failure.
“A smarter model generates better text, but it does not magically orchestrate complex, multi-step API interactions without deterministic guardrails.”
Reliability is an orchestration problem. The focus must shift from monolithic prompts to modular, constrained architectures.
Taming Non-Determinism: Architectural Patterns for Predictable Behavior
Implementing Semantic Guardrails and Output Parsers
Never let an LLM call an external API directly from a raw text generation. You must force structured outputs, utilizing strict JSON schema validation before a tool is ever triggered. If the output fails validation, the system should catch the exception and prompt the LLM to format its response correctly.
Here is a standard configuration pattern for forced structured output:
JSON
{
"name": "update_database",
"description": "Updates customer record.",
"parameters": {
"type": "object",
"properties": {
"customer_id": { "type": "string", "pattern": "^[A-Z0-9]{8}$" },
"action": { "type": "string", "enum": ["upgrade", "downgrade"] }
},
"required": ["customer_id", "action"]
}
}
The “Reflection” Pattern: Self-Correcting Agents Before Execution
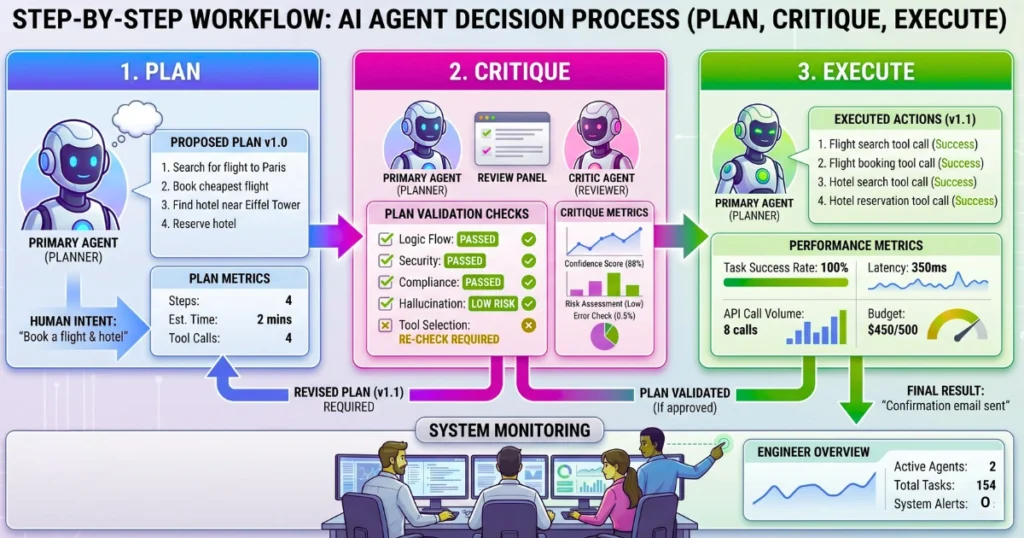
Designing a “Plan -> Critique -> Execute” loop is mandatory for high-stakes workflows. A secondary critic agent must double-check the primary agent’s logic against user constraints before firing irreversible functions. This introduces latency but drastically reduces destructive errors.
- Draft Phase: Primary agent generates a proposed sequence of actions.
- Review Phase: Critic agent evaluates the proposal against system rules.
- Execution Phase: System executes the validated plan.
Preventing Infinite Loops: Advanced State and Context Management
State Machines + LLMs: Hybrid Routing for Complex Workflows
Pure autonomous agents consistently fail at workflows requiring ten or more distinct steps. The solution is using finite state machines (FSMs) or graph-based orchestration frameworks like LangGraph.
You hard-code the overall flow and business logic, while letting the LLM handle the dynamic decision-making within individual nodes.
Distinguishing Between Short-Term Working Memory and Long-Term Vector Recall
Managing context window bloat is critical to preventing your agent from losing track of its goal. Dumping raw conversation logs into the prompt degrades reasoning performance. You must separate immediate execution context from historical data.
| Memory Type | Implementation | Best Use Case |
| Working Context | Summarized rolling buffer | Immediate task parameters and active state |
| Semantic Recall | Vector database (RAG) | Historical user preferences or static documentation |
| Episodic Memory | Key-value store | Past successful execution paths for similar tasks |
If You Can’t Measure It, It’s Not Production-Ready: Agent Observability
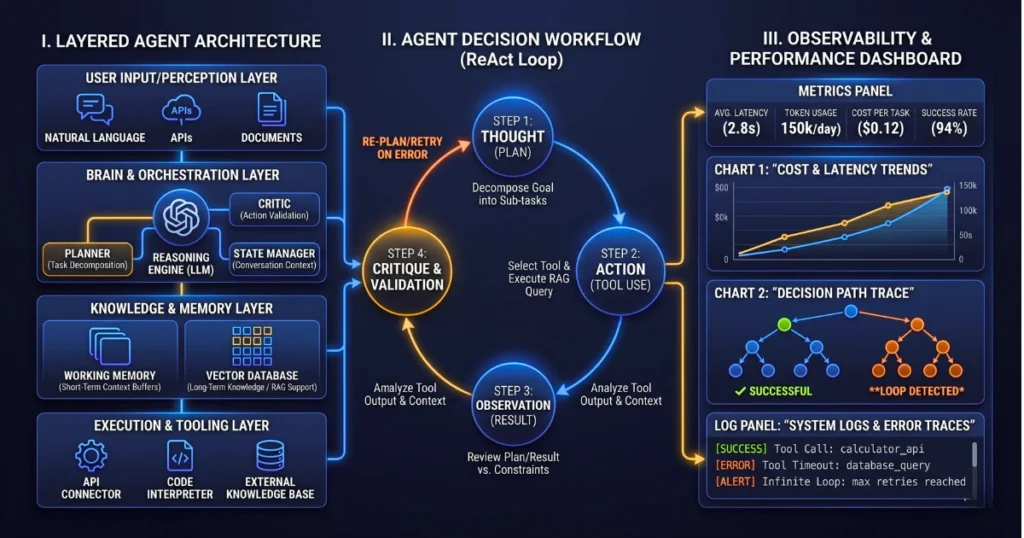
Tracing Multi-Step Agent Trajectories in Production
Logging the final output is useless when debugging an agent. You must capture the exact “thought process,” tracking the traces and spans of every tool selection and intermediate reasoning step. Tools that visualize the entire agent trajectory allow you to pinpoint exactly where the logic diverged.
Automated LLM-as-a-Judge Evaluation Pipelines
Traditional unit tests fail on non-deterministic LLM outputs. You need automated evaluation frameworks running in your CI/CD pipeline. These systems use a secondary, highly calibrated LLM to score the primary agent’s tool selection accuracy and task completion rate against a golden dataset.
Common Pitfalls: Why 90% of Agent Prototypes Fail in Production
The “God Agent” Anti-Pattern
Giving a single agent access to fifty tools and expecting it to choose correctly is a recipe for hallucinations. Narrowly scoped, single-purpose agents orchestrated by a master router perform significantly better. Divide and conquer to avoid falling for the AI adoption illusion where more access equals better results.
Over-Tooling and Insufficient API Descriptions
If the LLM doesn’t understand the exact nuance of the API, it will hallucinate arguments. Failing to write clear, semantic descriptions for your agent’s tools is a massive failure point. Treat your tool descriptions with the same rigor as user-facing API documentation.
Ignoring Graceful Degradation and Human-in-the-Loop (HITL) Fallbacks
What happens when the agent fails or its confidence score drops below a safe threshold? You must design explicit hand-offs to human operators for low-confidence decisions. A reliable system knows when to stop trying and ask for help.
Building for the Next Wave of Agentic Software
Deploying AI requires anticipating failure at every step of the orchestration layer. By implementing deterministic guardrails, separating state management from reasoning, and building rigorous evaluation pipelines, you can push past the PoC stage.
Audit your current agent architecture against these patterns today.



