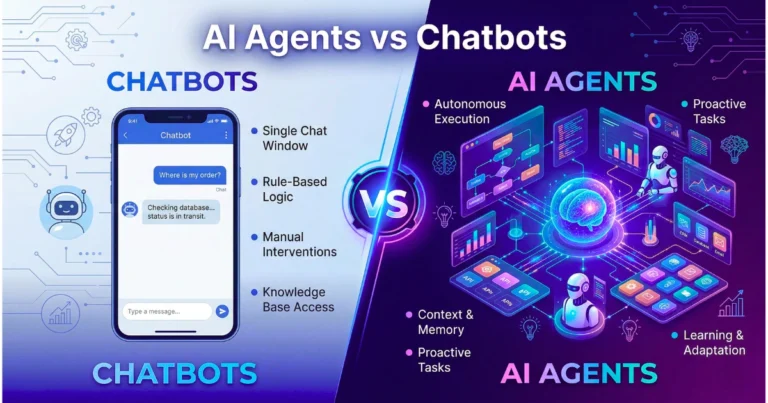
Context Windows Explained: Why AI ‘Forgets’ Mid-Conversation
I’ve watched this happen to people pushing an AI hard for the first time. They build up a long conversation. Often, it might go twenty or thirty exchanges deep. Suddenly, the model starts contradicting itself. For example, it asks a…