

AI memory failures are not caused by hallucinations.
The real problem is far more structural: modern AI systems still struggle to manage state reliably across complex workflows. The chatbot may appear intelligent in the moment, but underneath the interface, memory is often fragmented, delayed, and partially invisible to developers themselves.
As enterprises race toward autonomous agents and multi-agent orchestration, memory is becoming one of the most critical bottlenecks in AI infrastructure.
Systems can generate fluent responses, reason across large contexts, and execute tasks — yet still fail to consistently remember the information that actually matters.
This is the hidden architectural problem shaping the next phase of AI engineering.
Why AI Memory Is Harder Than It Looks
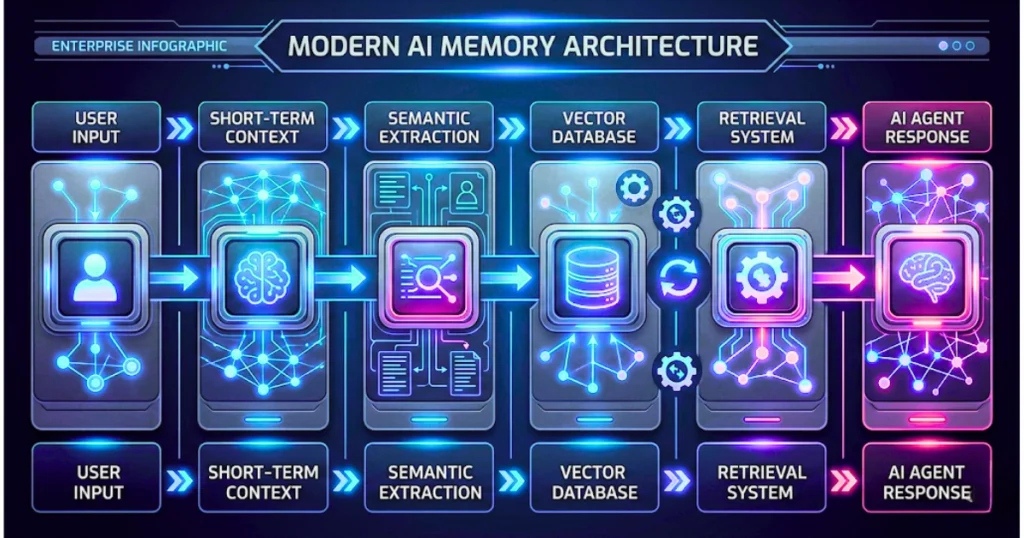
Most users assume AI memory works like human memory:
- important information gets stored
- context remains persistent
- future conversations build naturally on previous ones
But modern AI systems do not “remember” in the human sense. Instead, they operate across multiple memory layers:
- short-term conversational context
- vectorized semantic memory
- retrieval systems
- session state management
- orchestration frameworks
The complexity emerges when these layers stop behaving synchronously. A user may provide a critical constraint during a conversation, but the system cannot guarantee that the information has been successfully extracted, indexed, and made retrievable before the next workflow begins.
This creates what many developers now describe as orchestration drift: the gap between what the AI appears to know and what the infrastructure has actually persisted.
The Hidden Problem With Agentic AI Memory
Modern agentic systems increasingly rely on semantic memory architectures rather than simple chat history buffers. Platforms like Amazon Bedrock AgentCore Memory separate:
- short-term conversational events
- long-term semantic memory
- retrieval pipelines
- vector namespaces
On paper, this design improves scalability and reduces context-window overload. In practice, it introduces a new class of reliability problems.
The issue is visibility. Developers often lose direct control over:
- when information gets extracted
- which facts are prioritized
- how semantic summaries are generated
- when indexing becomes available for retrieval
The extraction layer becomes a black box. This means critical user instructions may not become accessible to downstream agents immediately — even though the conversation already moved forward. For enterprise orchestration systems, this delay becomes dangerous.
The Race Condition Nobody Talks About
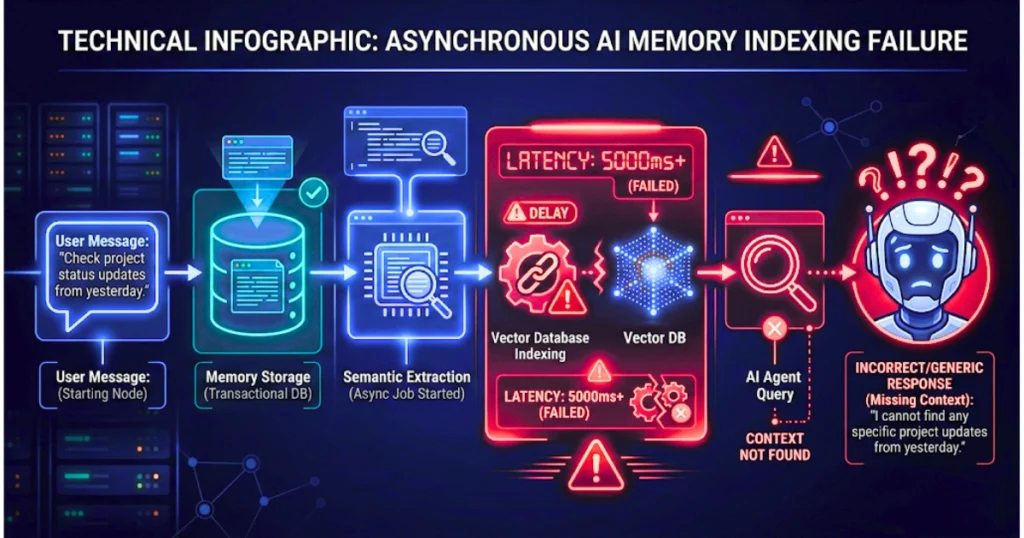
One of the biggest weaknesses in modern AI memory systems is asynchronous semantic indexing. Here’s what typically happens:
- A user sends important information
- The conversation layer stores the event
- Background systems extract semantic meaning
- The vector database indexes the information
- Retrieval systems eventually expose it
The problem is that these stages are rarely synchronous. An application may attempt memory retrieval milliseconds after storage, only to discover the information has not been indexed yet.
The result: empty retrievals, inconsistent agent behavior, failed multi-agent handoffs, and partial context awareness.
This creates hidden race conditions inside high-velocity AI workflows. The chatbot appears forgetful, but the actual failure occurs inside the memory pipeline itself.
Why Starter Toolkits Break at Scale
Many AI infrastructure platforms simplify onboarding through high-level starter toolkits and abstracted APIs. This works well for demos. It often breaks in production.
Developers initially assume these abstractions provide deterministic state guarantees across all memory layers. But once systems scale, hidden infrastructure complexity surfaces quickly.
For example:
- CLI-based provisioning may obscure infrastructure configuration
- semantic extraction pipelines may remain undocumented
- memory indexing delays may become unpredictable
- observability tooling may be insufficient
As a result, teams discover they cannot reliably audit when memory commits occur, whether extraction succeeded, how long indexing takes, or why retrieval failed.
The architecture becomes operationally opaque. This is one of the biggest challenges enterprises face when transitioning from prototype AI systems to production-grade agent orchestration.
Why AI Context Windows Aren’t the Real Solution
Many people assume larger context windows solve AI memory problems. They don’t.
Massive context windows reduce immediate retrieval pressure, but they introduce new operational issues:
- rising inference costs
- slower reasoning
- context dilution
- token inefficiency
- attention degradation
Long-term memory systems still become necessary. But once memory persistence enters the architecture, systems must solve semantic extraction, indexing reliability, retrieval accuracy, synchronization timing, and observability.
Memory becomes an infrastructure problem — not just an LLM capability problem.
The Shift Toward Deterministic AI Memory
Enterprise AI teams are now moving away from purely abstracted memory systems toward deterministic state management. This means:
- explicit memory verification
- retry-based retrieval logic
- observability middleware
- memory commit tracking
- event synchronization controls
Instead of assuming memory persistence succeeded, systems increasingly validate it before allowing downstream agent execution. This changes AI orchestration fundamentally. The future of AI reliability may depend less on model intelligence and more on memory determinism.
Why This Matters for Multi-Agent Systems
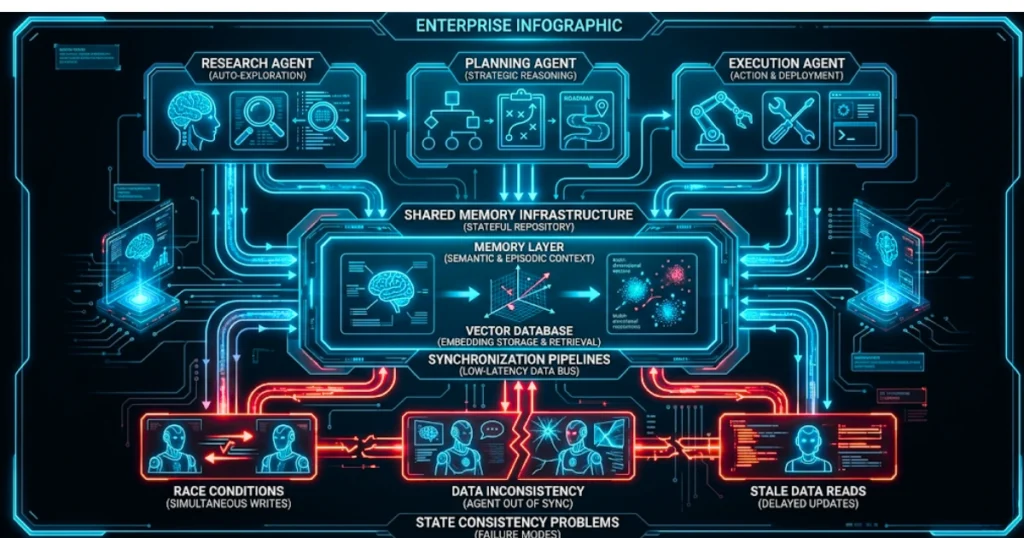
The problem becomes even more severe in multi-agent environments. When one agent passes context to another:
- timing mismatches matter
- retrieval delays compound
- semantic drift increases
- state inconsistencies propagate
A single failed memory commit can cascade across entire workflows. This is why many advanced AI systems still struggle with persistent personalization, long-running tasks, autonomous execution, and cross-agent coordination.
The issue is not always reasoning quality. Sometimes the system simply cannot guarantee shared state consistency.
The Real Future of AI Memory
The next wave of AI infrastructure will likely focus heavily on:
- memory observability
- state synchronization
- persistent agent identity
- deterministic retrieval pipelines
- memory governance frameworks
As AI systems become more autonomous, memory reliability becomes as important as reasoning itself. The challenge is no longer generating intelligent outputs. It is ensuring that intelligence remains coherent across time, workflows, and agents.
Final Thoughts
Chatbots do not “forget” because they are unintelligent. They forget because modern AI memory architecture is still fundamentally immature.
Behind every smooth AI interface exists a complicated orchestration layer attempting to synchronize transient context, semantic extraction, vector retrieval, persistent state, and autonomous execution. And today, those systems are still imperfect.
The companies that solve deterministic AI memory first will likely define the next generation of autonomous agents — because in the future of AI, memory may become more important than the model itself.



