

You have likely watched an AI chatbot confidently hallucinate an entire software architecture. You type a massive prompt demanding a full system refactor, and the model spits out a wall of code utilizing nonexistent libraries. The failure is not the model’s intelligence.
The failure is the architecture you forced it into. We are handing a surgeon a spoon and asking why the operation failed.
The “One-Shot Fallacy” is Killing Your AI Deployments
Relying on a single prompt to execute complex workflows assumes the model can produce perfect logic, from start to finish, with zero iteration. You would never write a 5,000-word technical document without hitting backspace or verifying a source.
Stop expecting a language model to do it.
The industry is aggressively pivoting away from passive chatbots toward autonomous agents. A regular chatbot operates on a linear track: it predicts the next word until it stops. An agent operates on a continuous feedback loop. It plans, acts, observes the result, and recalibrates.
This is the ReAct (Reasoning + Acting) loop.
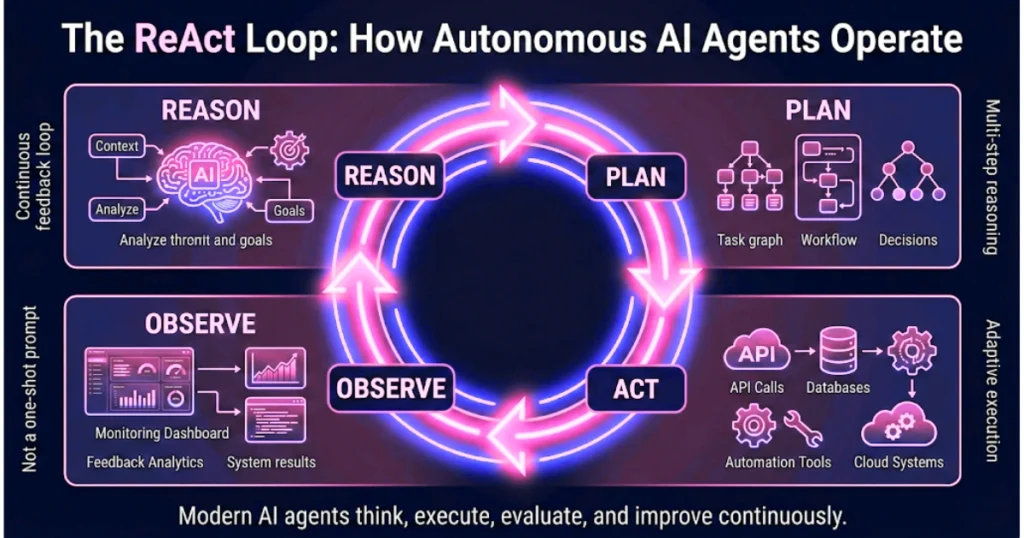
It is the architectural heartbeat of every production-grade system in 2026.
Autonomy is a Liability Without Strict Guardrails
Developers fundamentally misunderstand autonomy. They default to granting the model maximum freedom, assuming intelligence equals reliability. You must scale autonomy strictly based on the operational risk of the task.
- Level 1: The Scripted Agent (Low Risk, High Control):
The developer hardcodes the entire execution path. The model simply acts as a deterministic data parser. It pulls yesterday’s database metrics, summarizes the payload, and triggers an email script. The model makes zero routing decisions. It is a predictable, reliable cog. - Level 2: The Semi-Autonomous Agent (The Sweet Spot):
You define a strict goal and provide a constrained toolset. To process a customer return, the agent decides whether to query thelookup_orderAPI or thecheck_return_policydatabase based on the user’s input. The system adapts, but the execution boundaries are absolute. - Level 3: The Highly Autonomous Agent (Frontier Territory):
The agent defines its own execution graph and writes its own tools. It scrapes financial data, realizes the schema is malformed, writes a Python script to clean the payload, and executes the analysis. Without aggressive circuit breakers, these systems will silently consume massive API quotas while chasing hallucinated edge cases.
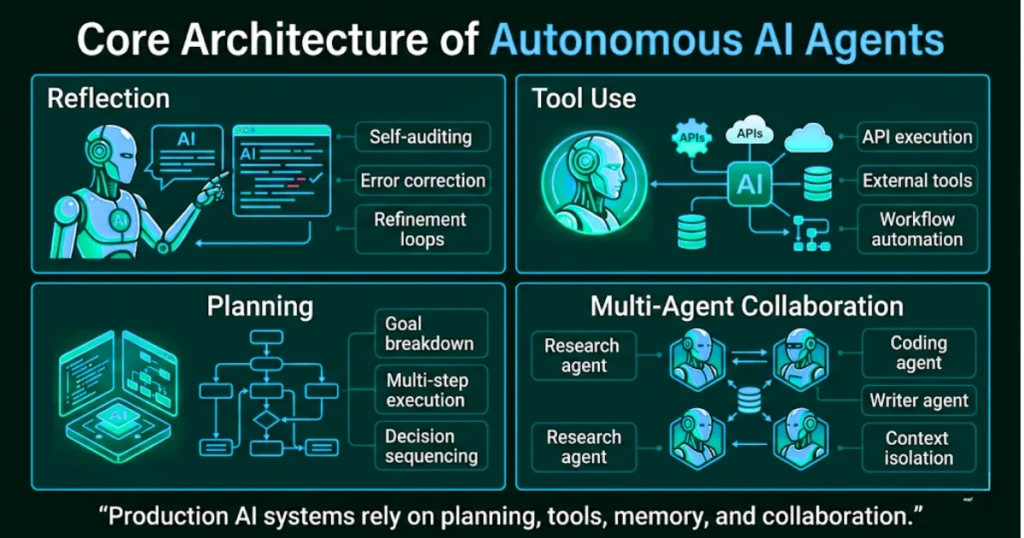
The Four Architectural Patterns of Production Agents
Every successful agentic deployment relies on a specific combination of these four execution patterns.
- Reflection:
Forcing the model to self-audit. Language models generate tokens sequentially. If they hallucinate in the first sentence, the error corrupts the entire output. Reflection forces the agent to critique its own draft before returning the payload to the user. Generating an output, identifying the missing context, and running a secondary refinement pass consistently boosts output accuracy by 20%. - Tool Use:
Giving the brain hands. An LLM without tools is simply a brain in a jar. Tools allow the model to mutate state across your enterprise infrastructure. The model does not execute the tool; it generates a structured JSON payload requesting an action. Your deterministic code executes the API call and feeds the result back into the context window. - Planning:
Breaking the impossible down. Agents require deterministic planning phases to prevent infinite loops. A planning sequence forces the model to split a complex goal into a traceable execution graph. If the agent proposes deleting a production database table as step one, your middleware catches the intent before the execution layer fires. - Multi-Agent Collaboration:
Siloing the context. Deploying a single mega-agent to act as a researcher, coder, and designer guarantees mediocre performance. You must deploy specialist nodes. A researcher agent isolates facts, passing the exact payload to a designer agent, which passes instructions to a writer agent.
Memory Must be Explicitly Engineered
Language models have zero native memory. Every single API invocation is a blank slate. If you want an agent to feel intelligent, you must engineer statefulness into the architecture.
- Short-Term Context (The Scratchpad):
This is the running log of the current session. Without it, the agent gets stuck in recursive loops, repeatedly querying the same failed endpoint. You must implement background summarization to compress this history, or the raw JSON logs will quickly exceed the context window limits and crash the application. - Long-Term Context (The Experience Layer):
Production agents save historical execution results to an external vector database. If an agent spends ten minutes debugging a malformed database column in Session 1, it writes the solution to long-term storage. In Session 2, the agent retrieves that exact insight before beginning its reasoning loop.
Scale Introduces Catastrophic Security Vectors
You are no longer defending against external hackers. You are defending against your own agent executing something accidentally catastrophic.
Scale introduces highly unpredictable security vectors. Never allow an LLM to directly execute high-stakes actions like issuing refunds or mutating database states. The LLM must request the action, routing the payload through a deterministic rules engine.
Furthermore, if your agent writes and executes code, it must happen inside a disposable, ephemeral sandbox. If the agent hallucinates a destructive bash command, it only destroys a container that was scheduled for deletion anyway.
Build the circuit breakers, silo the reasoning engines, and stop relying on prompt engineering to fix broken systems.



