

Most AI prototypes don’t fail because the idea is bad. They fail because the system behind them doesn’t exist yet.
Last year, we built an internal HR assistant that looked incredible in demos. Clean UI, fast responses, “smart” answers — the usual early wins.
Then we opened it up to real users. Within 72 hours:
- Queries started timing out at 20–30 seconds
- API costs jumped nearly 4x
- And the model confidently invented HR policies that didn’t exist
Nothing was technically “broken.” But the system wasn’t built to survive reality.
That’s the gap most teams underestimate: a working prototype is not a scalable product.
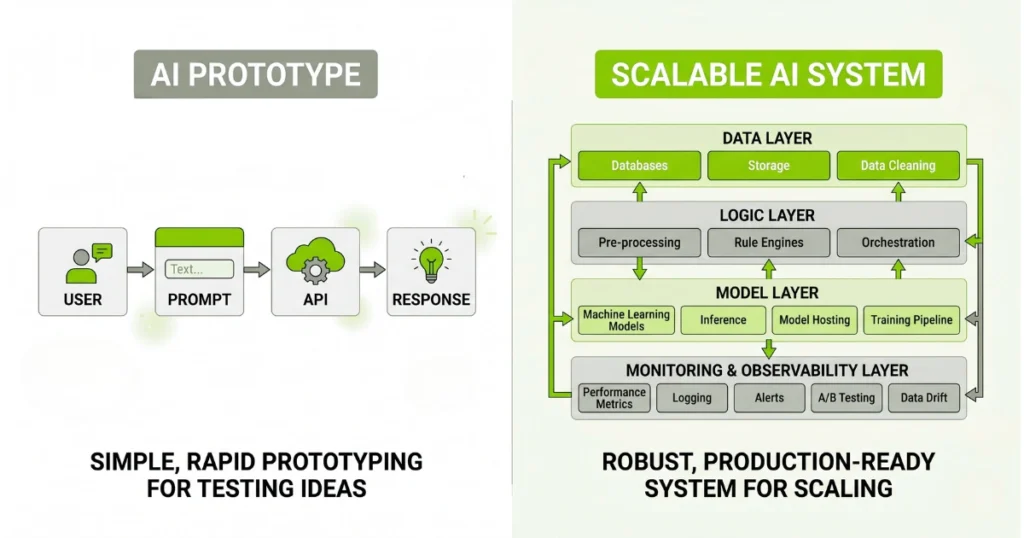
The Hard Truth: AI Wrappers Are Not Products
There’s a belief floating around that: “If I use the right model and write good prompts, I’ll have a competitive edge.”
You won’t. Models change. Prompts break. APIs evolve.
If your entire product is: User → Prompt → API → Response
then your entire product can be rebuilt by someone else in a weekend. Your defensibility is not the model. It’s everything around it.
That includes:
- How you collect and structure data
- How your system improves over time
- How deeply you integrate into real workflows
That’s the difference between a demo… and a business.
Where Most Teams Break: The Transition Phase
The biggest mistake isn’t technical — it’s mental. Teams stay in “prototype mode” too long.
They treat:
- prompts like code
- APIs like infrastructure
- and logs like optional
But production AI systems behave differently. You need separation across your modern AI stack:
- The model layer (replaceable)
- The logic layer (yours)
- The data layer (your moat)
Once you decouple these, everything becomes easier to scale, debug, and optimize. Without that separation, every issue becomes chaos.
Scaling Isn’t About Traffic — It’s About Control
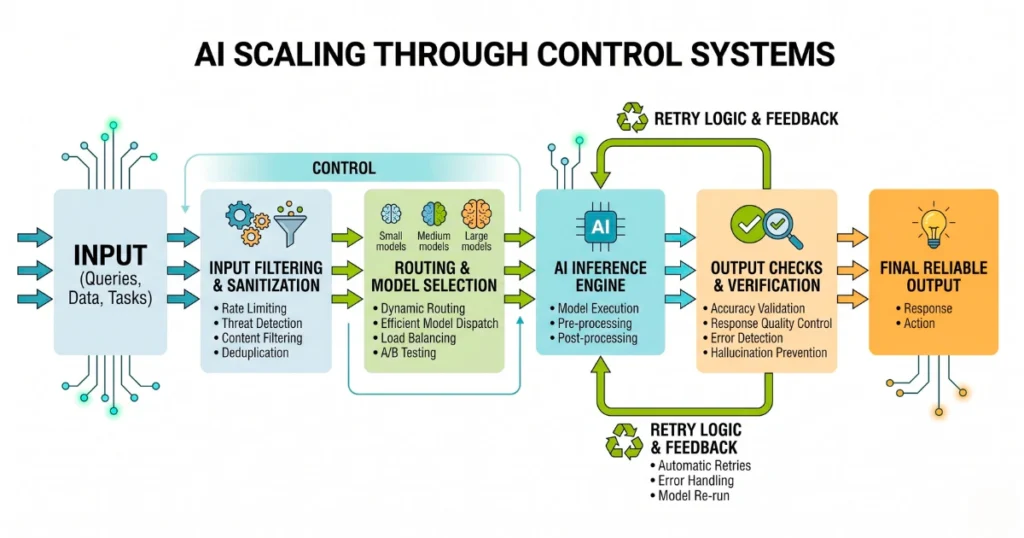
A lot of developers think scaling AI means handling more users. That’s only half the problem.
The real issue is: handling more uncertainty. Because every user input is unpredictable.
So instead of scaling servers, you need to scale control systems:
- What gets sent to the model
- Which model handles which task
- How outputs are validated
- When to retry vs fail
Without control, more users = more expensive mistakes.
The Unit Economics Problem Nobody Talks About
Here’s where most AI products quietly die. Not because they crash — but because of the hidden cost of AI in business.
If every request hits a premium model:
- your margins disappear
- your pricing breaks
- your growth stalls
The fix is simple in theory but rarely implemented well: Stop treating all requests equally. Different tasks deserve different compute:
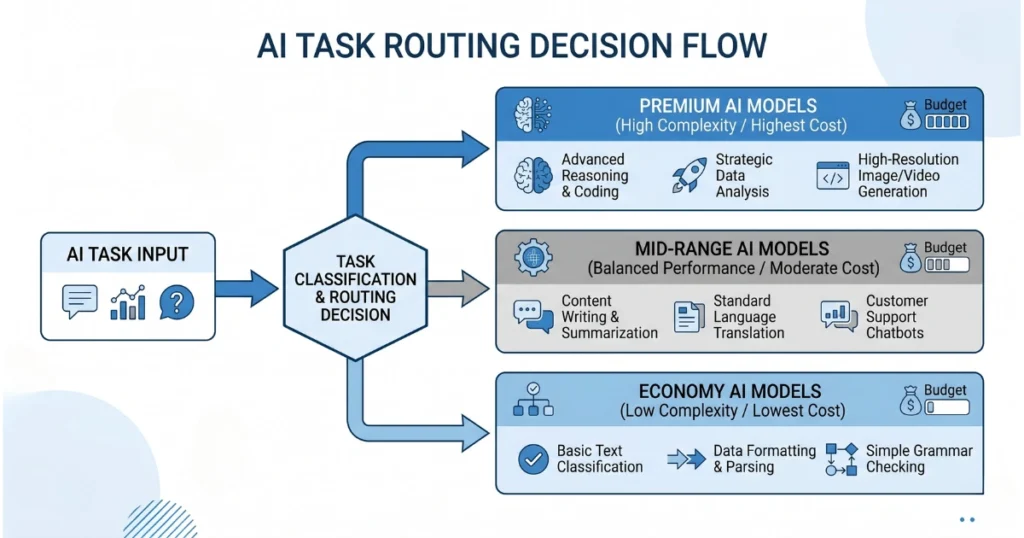
- Simple extraction → cheap/local model
- Standard queries → mid-tier API
- Complex reasoning → premium model
This one shift alone can cut costs dramatically. Add caching on top of that, and your system starts behaving like an actual product — not a money leak.
What Actually Creates a Moat in 2026
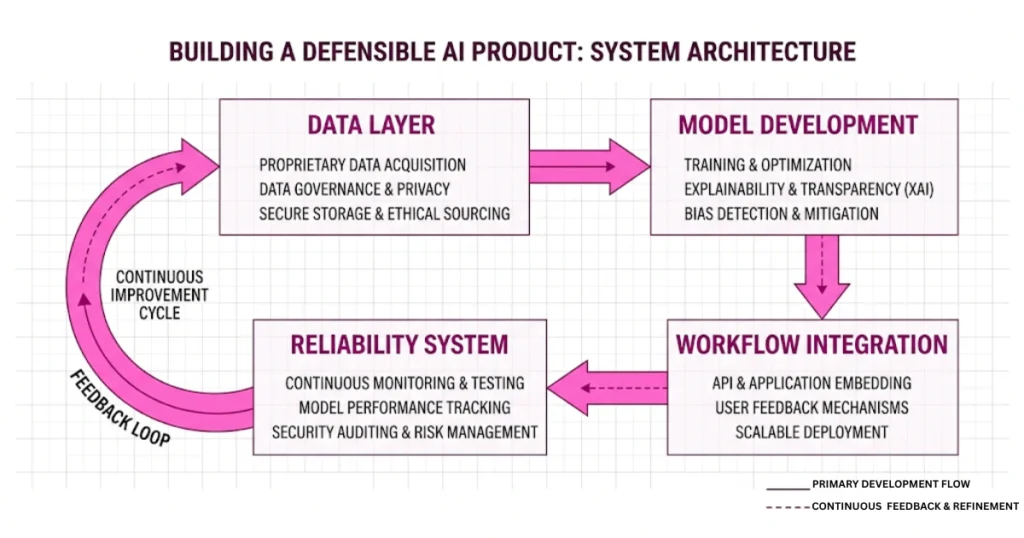
It’s not:
- your prompts
- your UI
- your model choice
Those are all replaceable. Real defensibility comes from compounding advantages:
1. Proprietary Data Loops
Your system should improve with usage. Every interaction should refine responses, improve retrieval, and reduce errors over time. If your system isn’t learning, it’s stagnating.
2. Workflow Integration
Standalone AI tools are easy to replace. But once your system plugs into internal tools, automates real tasks, and becomes part of daily operations… it becomes hard to remove. That’s where switching costs come from, and how you finally break through the automation ceiling.
3. System Reliability
This is underrated. If your AI times out, breaks formatting, or gives inconsistent outputs, users lose trust fast. And once trust is gone, no model upgrade will fix it.
The Mistakes That Kill Most AI Products
Not theoretical mistakes — real ones you’ll hit.
Treating hallucinations like bugs
They’re not bugs. They’re behavior. You don’t “fix” them. You design around them.
Ignoring system observability
If you can’t trace what input went in, what context was retrieved, or what output was generated, you can’t debug anything.
Scaling stateless systems
Users expect continuity. If your AI forgets everything between sessions, it feels broken — even if technically correct.
Over-trusting APIs with sensitive data
This one is risky. If you’re not filtering inputs, managing retention, and controlling exposure, you’re creating long-term problems.
The Shift That Changes Everything
At some point, every serious AI builder realizes: “The model is just one component.”
And once you see that, your priorities change. You stop asking: “Which model is best?” And start asking:
- “What happens when the model fails?”
- “How does my system recover?”
- “How does it improve over time?”
That’s when you move from building demos… to building products.
Final Thought
Getting an AI feature to work is easy. Making it reliable, cost-efficient, and defensible? That’s where almost everyone drops off.
If your system depends on a single model, has no fallback logic, and doesn’t improve with usage… it’s not ready yet.
Fix that layer first. Because once real users hit your system, they will find every weakness you ignored.



