

Most AI projects don’t fail because the model is weak. They fail because everything around the model is unprepared.
The uncomfortable part? Teams usually realize this after the prototype works.
That’s the trap. A working demo creates the illusion that the hard part is done. In reality, it hasn’t even started yet.
The project never had a real job to do
A lot of AI initiatives begin with a vague intention: “we should use AI here.”
That sounds reasonable until you ask a simple question: What decision is this system supposed to improve?
If that answer isn’t precise, the project drifts. It turns into exploration—features, experiments, iterations—without a clear endpoint.
And when it’s time to move toward production, there’s nothing solid to anchor it:
- No measurable outcome
- No clear owner
- No urgency to deploy
At that point, stopping the project feels easier than defining it properly.
The data problem shows up late—and hits hard
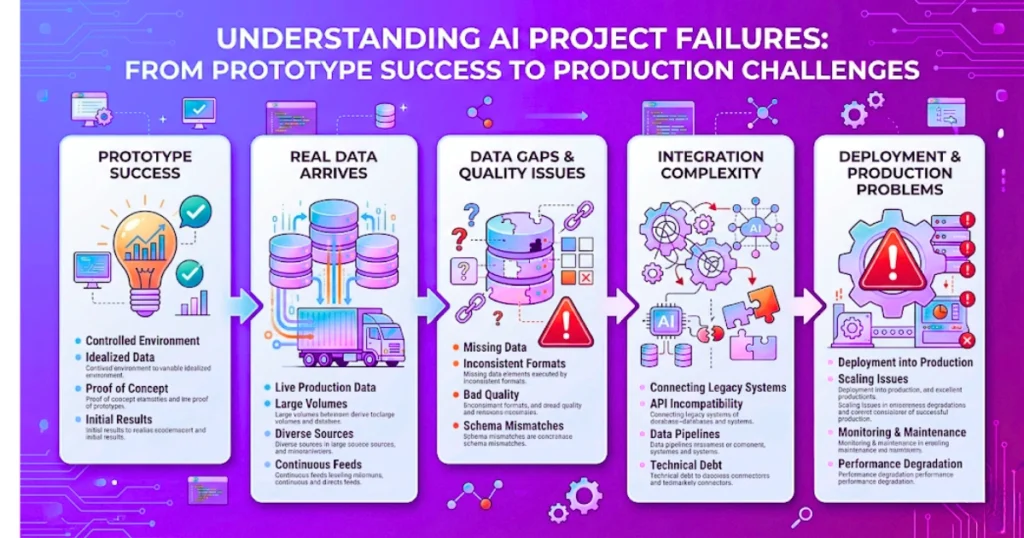
On paper, the data exists. In practice, it’s scattered across systems, inconsistent, and full of gaps.
This usually gets discovered too late. During prototyping, teams work with cleaned samples. Things look stable. Accuracy looks promising. Confidence builds.
Then real data enters the system.
- Customer names don’t match across platforms
- Fields are missing in critical cases
- Historical data is biased or incomplete
The model hasn’t failed—the assumptions about the data have.
And fixing data pipelines is slower, more political, and far less exciting than building models. That’s where many projects stall.
A working model that nobody actually uses
There’s a difference between a model that performs well and a system that fits into real work.
Most teams underestimate this. If using the AI requires:
- Switching tools
- Adding extra steps
- Waiting longer than the current process
…people won’t use it. Not because they’re resistant to change—because they’re busy.
In real environments, convenience beats capability every time. So the model ends up in a demo environment, occasionally shown, rarely used.
Expectations quietly sabotage the rollout
There’s often an unspoken belief that AI will behave like a deterministic system. It won’t.
Even a good model:
- Gets things slightly wrong
- Struggles with edge cases
- Produces outputs that need interpretation
If stakeholders expect near-perfect accuracy, trust collapses the first time something looks off. What could have been positioned as decision support gets judged as decision replacement—and fails that test.
Ownership disappears right when it matters
Early on, there’s momentum. People are building, testing, presenting.
Then the question comes up: Who owns this in production?
Not in theory—in practice.
- Who monitors performance weekly?
- Who handles failures?
- Who approves changes?
- Who answers when something goes wrong?
If those roles aren’t defined, deployment becomes a risk nobody wants to take. So the project lingers. Not rejected—just not moving.
Users don’t reject the system—they route around it
This is one of the most common failure patterns, and it’s easy to miss. Nobody files a complaint. Nobody escalates.
They just stop using it.
- Maybe the output is hard to interpret.
- Maybe it slows them down at key moments.
- Maybe they don’t fully trust it yet.
So they go back to the old process. From the outside, the system still “exists.” In reality, it’s already dead.
No baseline, no proof, no budget
Even when the system works reasonably well, there’s often no clear way to prove it.
- What was the error rate before?
- How long did decisions take previously?
- What did the manual process cost?
If those numbers don’t exist, improvement becomes subjective. And subjective value doesn’t survive budget discussions.
The pattern is predictable
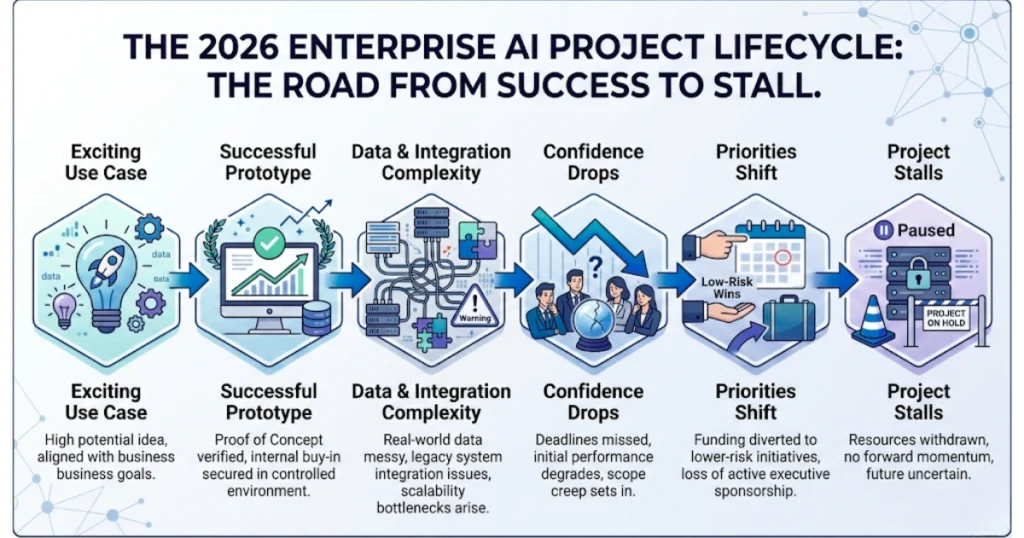
The lifecycle looks like this:
- A promising use case gets attention
- A prototype delivers encouraging results
- Complexity shows up (data, integration, edge cases)
- Confidence drops
- Priorities shift
The project doesn’t fail in a single moment. It just loses momentum until it’s no longer relevant.
What actually changes the outcome
The projects that reach production don’t feel experimental from the start. They’re tied to something concrete:
- A decision that costs money when it’s wrong
- A process that’s clearly inefficient
- A workflow people already depend on
Data work starts early, not after the model looks good. Users are involved before rollout, not introduced to it at the end. And ownership is explicit—someone is responsible not just for building it, but for keeping it useful over time.
There’s no single technical breakthrough that separates successful AI projects from failed ones. It’s usually simpler than that.
The successful ones close the gap between what works in a demo and what survives in the real world.



