
Introduction: The Friday Deployment That Breaks Everything
It’s 4:00 PM on a Friday. Your team just shipped a new AI-powered document assistant. Initially, early feedback looks great. Traffic is climbing, and naturally, everything feels like a massive win.
Then, things suddenly start breaking.
For instance, latency jumps from 2 seconds to 45. Logs show a massive PDF upload completely blowing up your context window. Consequently, your single-provider API starts timing out. Because your app is basically just a direct pipe to the model, the failure cascades—and suddenly your entire system is down.
As a result, your weekend is ruined.
If this sounds familiar, you’re certainly not alone. In fact, most AI projects work perfectly in demos but fail immediately in production. That’s primarily because they’re not real systems. Instead, they are just wrappers.
Ultimately, this guide is about what it actually takes to build scalable AI systems that survive real-world usage.
The Prototype Trap: Why Most AI Apps Never Scale
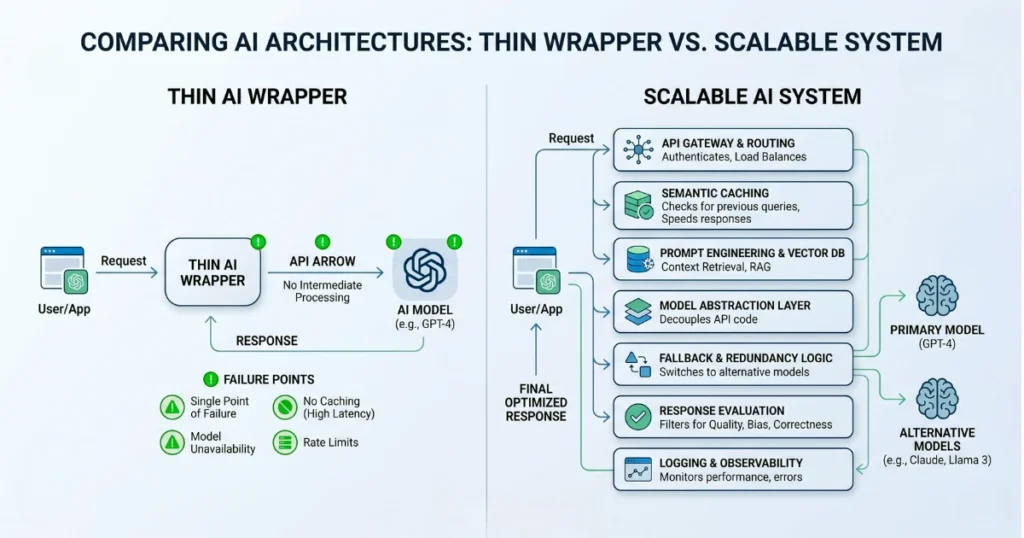
Most AI apps start the exact same way: with a simple API call, a clever system prompt, and a clean demo.
And for a while, it works perfectly. However, here’s the harsh truth: Prompts are not a moat. Sure, they get copied. Eventually, they break. And naturally, they drift over time.
Therefore, real defensibility comes from:
- Robust data pipelines
- Custom routing logic
- Relentless evaluation systems
When to Stop Using Frameworks and Build Your Own Layer
If you’re currently working with modern AI frameworks, you’ve probably felt this specific friction. At first, they undoubtedly help you move fast.
However, at scale, they often become black boxes. Consequently, debugging becomes incredibly painful. Furthermore, root-cause errors become significantly harder to trace.
Rule of Thumb: The very moment you start writing hacky workarounds just to force a framework to behave—stop. Basically, that is your clear signal to build a custom middleware layer. After all, control always beats convenience in production systems.
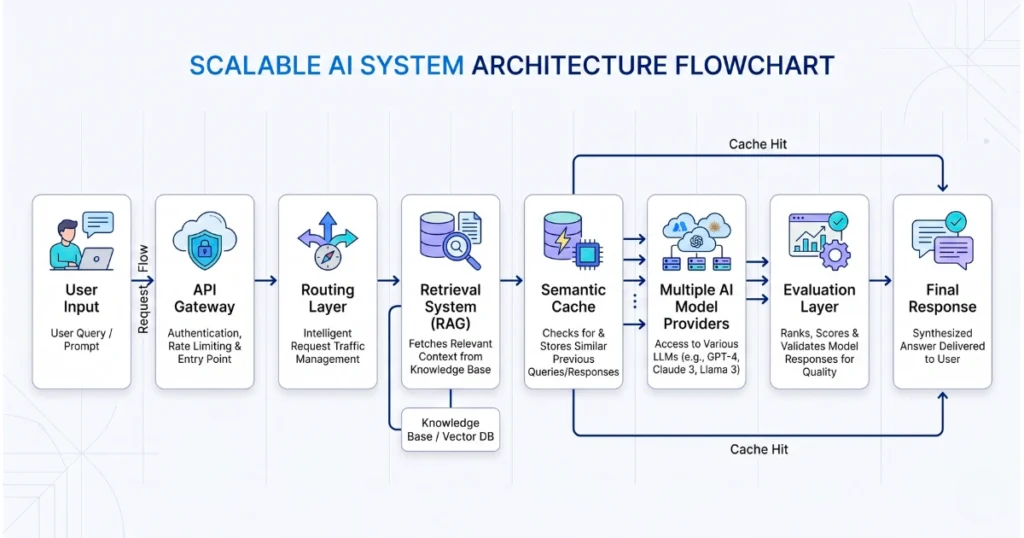
RAG vs Fine-Tuning: Stop Using LLMs Like Databases
A surprisingly common mistake is treating LLMs like a standard storage system. Frankly, they’re not. Instead, LLMs are reasoning engines — not knowledge bases.
Better Approach: Instead of attempting to force knowledge into the model’s weights: Simply improve your RAG pipeline quality.
In almost all real-world cases, adding a cross-encoder reranker and improving your retrieval accuracy delivers far better ROI than attempting costly fine-tuning.
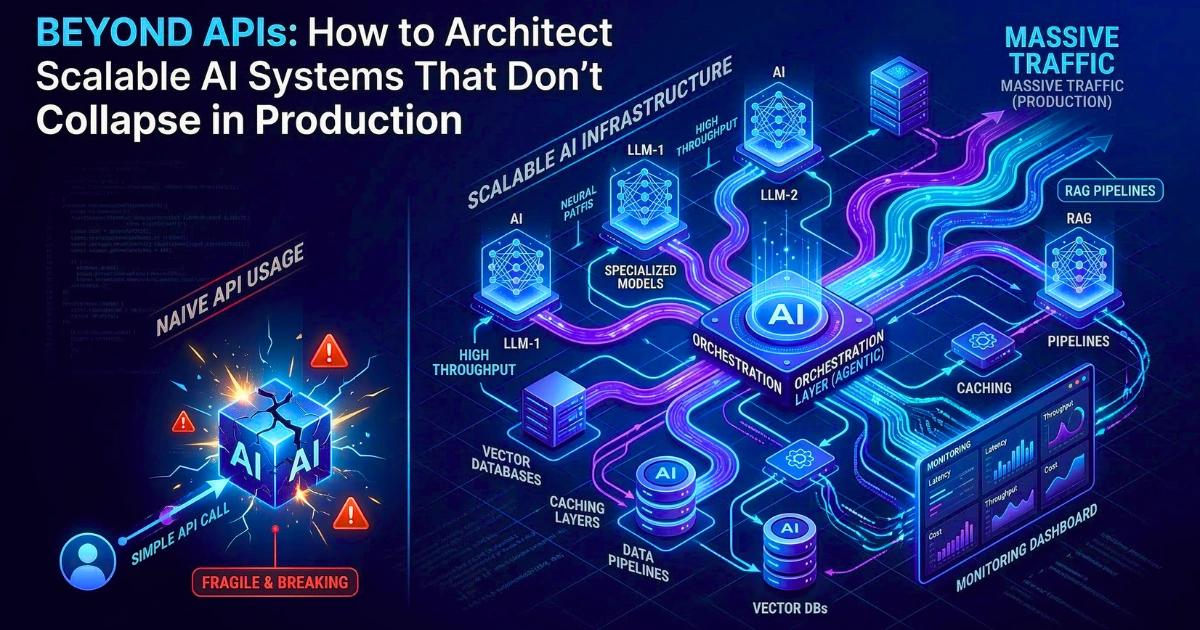
The Core Pillars of Scalable AI Systems
To build systems that don’t immediately collapse, you obviously need to optimize for three things: Cost, Speed, and Reliability. Here is exactly how to do that.
1. Dynamic Routing for Cost Control
First, stop sending every single request to your absolute most expensive model.
- Real Scenario: For example, in an e-commerce AI setup:
- For a complex comparison → route to a powerful model
- Conversely, for a simple query → route to a lightweight model
Ultimately, this one architectural change alone can reduce costs dramatically.
2. Semantic Caching to Reduce Token Costs
Secondly, if 500 users ask the exact same question, you absolutely should not pay 500 times to process it.
- What is Semantic Caching?
Essentially, it stores previous answers and instantly reuses them when mathematically similar queries appear. - Result: As a direct result, you get significantly faster responses, much lower API costs, and noticeably better scalability.
3. Graceful Degradation & Vendor Independence
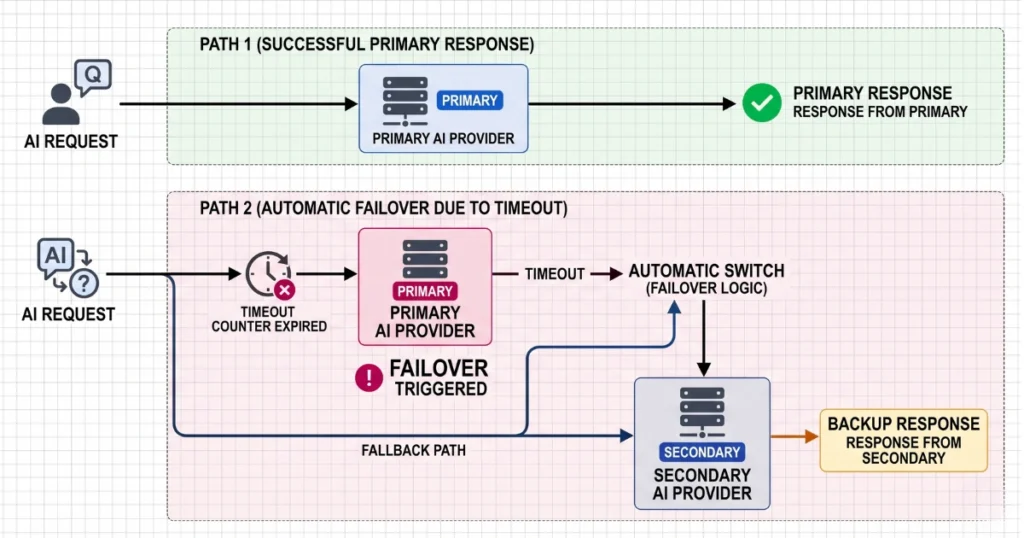
Finally, never hardwire your business to a single AI provider. Obviously, if their server goes down → your app goes down with it.
- The Fix:
- First, add strict try/except timeouts (e.g., 5–7 seconds).
- Next, implement silent fallback models.
- Above all, fail silently so end-users never actually see a system timeout error.
Dangerous Myths That Kill AI Systems
1. The “Bug” Fallacy
First and foremost, hallucinations are not software bugs. Rather, they are a fundamental feature of how probabilistic models actually work. Therefore, you shouldn’t try to eliminate them entirely — instead, you must design orchestration systems specifically to catch them.
2. The Context Window Trap
Similarly, more context does not necessarily equal better answers. In reality, stuffing too much context into a prompt creates noise. Specifically, it reduces accuracy, exponentially increases cost, and thoroughly confuses the model’s recall abilities.
3. The “Prompt Engineering = Architecture” Myth
Lastly, prompts are inherently fragile. Specifically, they break whenever models update or user behavior suddenly changes. Thus, they are absolutely not a viable system design strategy.
Evaluating AI Systems in Production
Testing AI is notoriously hard, primarily because the outputs change every single time.
What You Actually Need to Measure:
- Retrieval Accuracy: Did the system successfully fetch the right internal data?
- Generation Quality: Subsequently, did it summarize that data correctly without hallucinating?
The Only Real Solution: Continuous Evaluation Consequently, you can’t simply rely on static, one-off testing. Instead, you must use LLM-as-a-Judge systems:
- First, a smaller model constantly evaluates your outputs.
- Then, it scores them for accuracy and consistency.
- Finally, it monitors production logs continuously.
Ultimately, this workflow is your only real safety net.
From Fragile Apps to Real Infrastructure
Moving away from a simple demo into a resilient production system is undoubtedly painful. Yet, it is entirely necessary.
Therefore, stop focusing on clever prompts and quick demos. Instead, start engineering robust routing systems, solid data pipelines, and relentless evaluation loops.
Final Thought: Audit Your System Today
Take a moment to ask yourself:
- First, where exactly are my single points of failure?
- Second, what happens to my application if my primary API goes down tomorrow?
- Finally, do I actually have programmatic cost controls in place?
If you don’t have perfectly clear answers to those questions, your system clearly isn’t production-ready yet. Fix it now — before your next Friday afternoon deployment turns into an absolute disaster.
FAQs
- Why do most AI apps fail in production?
Primarily because they rely on simple API wrappers without implementing proper architecture, dynamic routing, or strict cost controls. - Is RAG better than fine-tuning?
Generally, yes — especially for highly dynamic or frequently changing enterprise data. - How do I reduce AI API costs?
Specifically, you should use smaller open-source models for simple tasks, implement semantic caching, and utilize dynamic routing. - Should I depend on a single AI provider?
Absolutely not. Instead, you must always design your architecture for failover and redundancy.



