

Indeed, the industry’s obsession with million-token context windows is an engineering disaster masquerading as a breakthrough. Vendors are peddling massive memory capacities on platforms like Amazon Bedrock as a silver bullet for dumping raw enterprise databases into a prompt.
Consequently, they willfully ignore the sheer physics of compute constraints. The harsh reality is that the context window operates as a brutally strict budget. It caps the sum of your input and output tokens across every single API call.
You are not buying infinite computation. You are buying a highly volatile latency trap. Because of this, the system demands merciless input validation and aggressive filtering mechanisms just to keep from collapsing under its own bloat.
Stop treating LLM APIs like an infinite S3 bucket
For instance, we recently audited a legal-tech firm that bought into the “unlimited context” hype. They dumped a 900,000-token merger document into a single prompt, expecting the model to flawlessly summarize liability clauses.
The system suffered severe “loss in the middle” degradation.
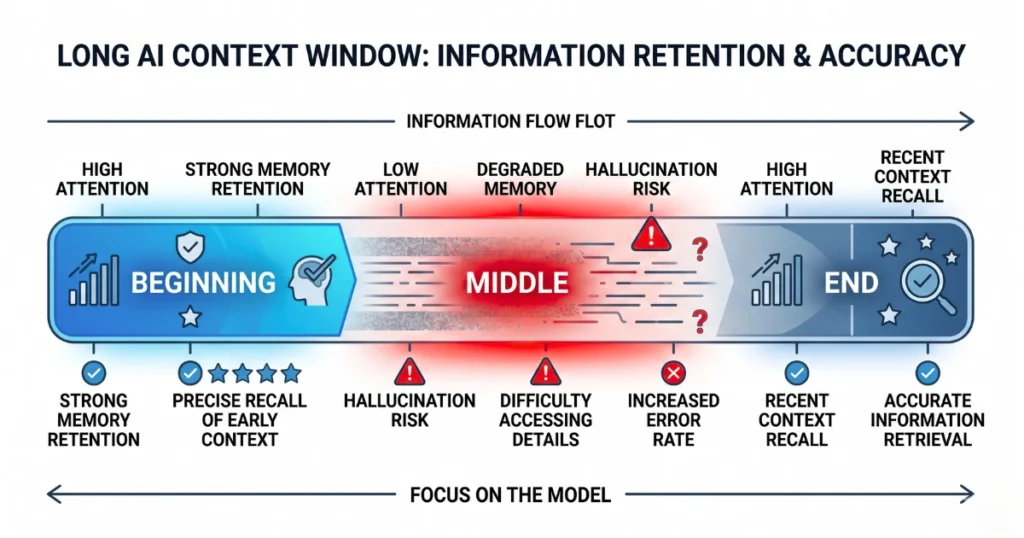
Instead of failing loudly, the model completely hallucinated. It ignored a critical indemnity clause buried on page 400.
As a result, it confidently generated a clean risk report, and the executives nearly signed a contract containing a toxic $10 million liability trap.
The only thing that stopped the disaster was a junior paralegal doing a manual spot-check on a Sunday night. Predicting how output quality degrades exponentially at scale is the only wall standing between your application and a cascading failure in production.
Dynamic context compression is your only defense
Summarization loops and strict prompt truncation are the actual foundation of generative AI workflows. However, development teams treat them as an afterthought while building bloated architectures that crash against aggregate service quotas.
When those architectural mitigations fail, developers usually do something exponentially worse out of sheer laziness. They write error handlers that spit the specific context window limit back to the client.
Furthermore, this effectively hands bad actors a mapped blueprint of your infrastructure for environmental enumeration.
Ultimately, you must return a generic 400 error, drop the payload entirely, and close the TCP connection before an attacker maps your backend.



