

Why Your OpenAI Bill Starts Growing Faster Than Expected
When teams first figure out how to build AI applications, they rarely begin with cost optimization in mind. The early goal is usually simple: get the feature working.
You connect a chatbot, write prompts, and verify the responses. The API bill barely moves because only a handful of people use the tool. The problem appears later.
A few hundred users become a few thousand. Features that looked harmless during development start running constantly in production. A prompt that seemed small suddenly executes millions of times.
In most cases, the increase doesn’t stem from one major mistake. It usually comes from several smaller decisions stacking on top of each other:
- Sending full chat history every request
- Using expensive models everywhere
- Generating long responses when short ones would work
- Repeating requests that you could have reused
- Running background work in real time
Individually they don’t look serious. Together they create a surprisingly large bill.
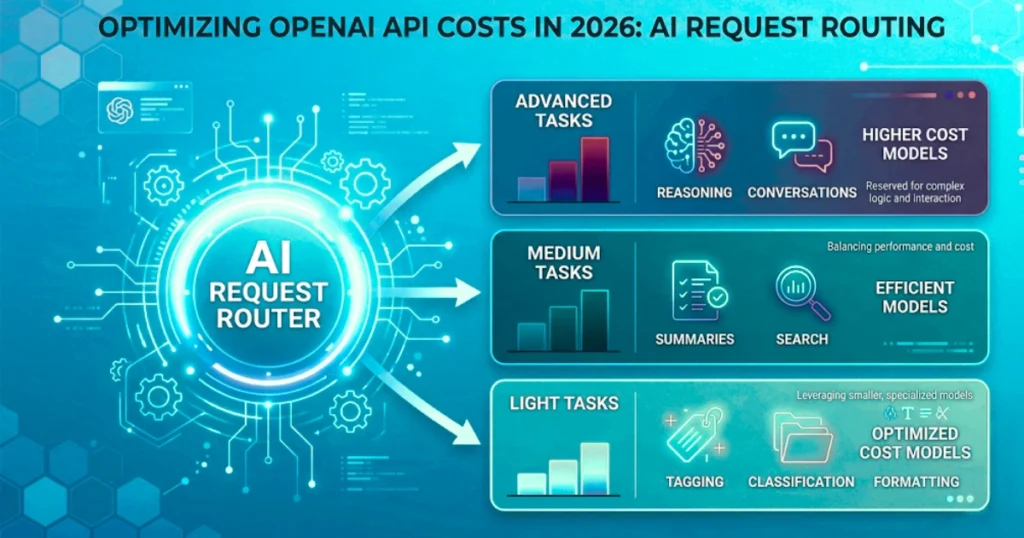
Start With Model Selection Before Touching Anything Else
One thing that happens often during development is using the same model for everything.
It makes sense at first. Stronger models usually produce better results, so they become the default choice across the application. After a while, the same model ends up handling search queries, text formatting, tagging, summaries, and user-facing conversations.
The issue is that many of those tasks don’t require advanced reasoning.
Text classification, category detection, entity extraction, formatting, or routing requests are usually much lighter tasks. Users rarely notice differences there.
The places where quality becomes visible are different:
- Ambiguous user requests
- Long-form generation
- Complex reasoning
- User-facing responses where wording matters
Some teams place a small routing layer in front of the API to classify requests before choosing a model. Strategically selecting between specialized vs. generalist AI ensures easy work stays cheap, while difficult requests move to stronger models only when necessary.
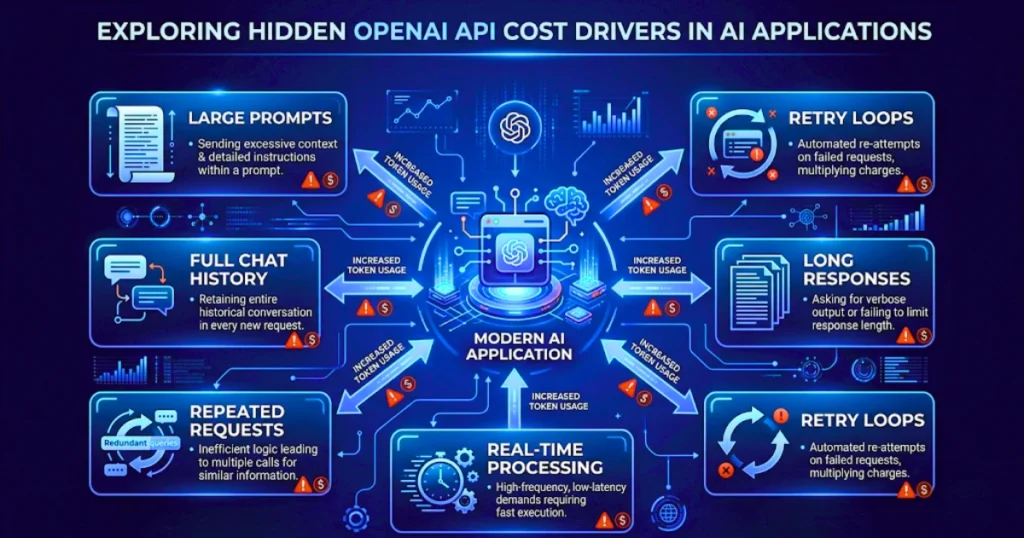
Large Prompts Quietly Become Expensive
Token usage tends to grow slowly, which is why it often goes unnoticed.
A system prompt starts small:
You are a helpful assistant.
Then new requirements appear. Developers introduce formatting rules. They insert safety instructions. Next, they provide examples. Finally, they account for edge cases.
Months later, the prompt spans several paragraphs, and the application transmits it with every request.
Managing AI memory and conversation history creates a similar problem.
Keeping full history sounds useful in theory, but older messages gradually lose value. Sending everything repeatedly means paying for context that the model may not even use anymore.
Keeping recent messages while replacing older conversations with compact summaries usually works better.
Response size matters too.
If users need a short answer and the model generates ten paragraphs, you spend extra tokens without adding much value. This is a classic example of the token trap of “unlimited context” quietly draining budgets month over month.
Entire Documents Don’t Need to Travel With Every Request
A common shortcut in AI applications involves pushing large amounts of information directly into the prompt.
For example:
- Entire PDFs
- Knowledge-base articles
- Documentation collections
- Internal company files
It works during early testing because accuracy appears higher when more information is available.
The downside shows up later.
Large context windows become expensive, and sending unrelated information can actually reduce response quality.
Instead of pushing raw data, leveraging the cost-efficiency of fine-tuning vs. RAG approaches usually scales better.
Store the content separately in a dedicated vector database, search for relevant sections, and only send those sections into the request.
Instead of sending a 50-page document, the model might receive only two or three relevant chunks. Lower token usage is usually the first improvement people notice. Faster responses often come right after.
AI Applications Repeat More Work Than People Expect
Even applications that look unique often process very similar requests underneath.
Users ask variations of the same questions. Dashboards regenerate nearly identical summaries. Internal tools repeatedly analyze overlapping data.
Without caching, the API handles the same work over and over.
Exact-match caching handles identical requests, but semantic caching can go further by recognizing requests that are similar enough to reuse previous results.
For things like FAQ systems or knowledge assistants, this can remove a noticeable amount of unnecessary API traffic. The user still gets an answer instantly, but the application avoids paying for the same task repeatedly.
Some AI Work Does Not Need To Happen Immediately
Real-time processing becomes the default in many products simply because it’s easier to build around.
But not every task actually needs instant generation.
You can often generate suggested tags, recommendation lists, article summaries, content labels, and similar features before users even ask for them.
Instead of creating them at request time, background jobs can prepare and store them. When users arrive, the system has already completed the work.
The interface feels faster while API usage becomes more predictable.
Retry Logic Can Quietly Increase Costs
Most people think of API spending in terms of successful requests. Failed requests can create problems too.
Temporary timeouts, network interruptions, or traffic spikes sometimes trigger retry systems that repeatedly send the same request.
Without limits, one request can become several. A small issue during peak traffic can unexpectedly multiply usage.
Retries usually work better when developers treat temporary failures differently from permanent ones, placing strict limits on how many times a request should attempt to execute.
Monitoring Usually Reveals Unexpected Things
Many teams only look at the monthly bill. The problem is that the total number rarely explains where the money actually went.
Breaking usage down by feature often tells a different story. Sometimes the chatbot isn’t the expensive part at all.
Background summarization jobs, recommendation systems, or automated processing pipelines occasionally end up consuming more tokens than the features users directly interact with.
Without tracking individual features, these patterns contribute to the hidden cost of AI in business, staying concealed until the bill becomes difficult to ignore.



