

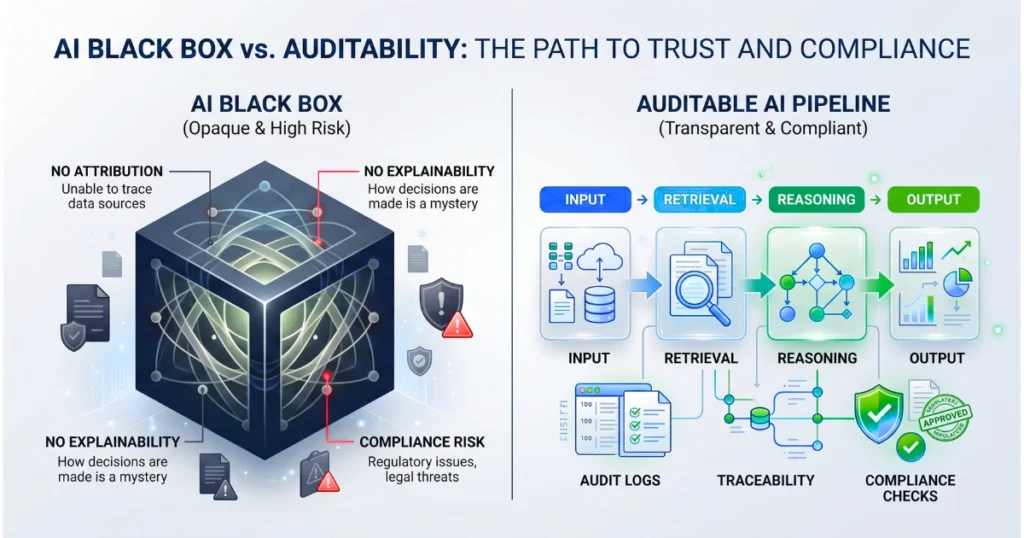
“Black Box” Outputs Void Insurance Deployments Immediately
The core failure mode during the recent underwriting assistant rollout was not a hallucinated policy limit, but a fundamental inability to satisfy the National Association of Insurance Commissioners (NAIC) Model Bulletin requirements for an Artificial Intelligence System (AIS) Program.
When the legal team demanded an explainability matrix for the model’s claim denial recommendations, the engineering team realized they had built a high-performance text generator with zero training data attribution.
Humans could not examine the models to understand the output origination, directly violating the NAIC demand for explainability, safety, and transparency.
The entire deployment stalled for three weeks while architects scrambled to retrofit ReAct and Chain of Thought (CoT) prompting into a system designed for raw speed over auditability. The model was fast, but speed is legally useless without an audit trail.
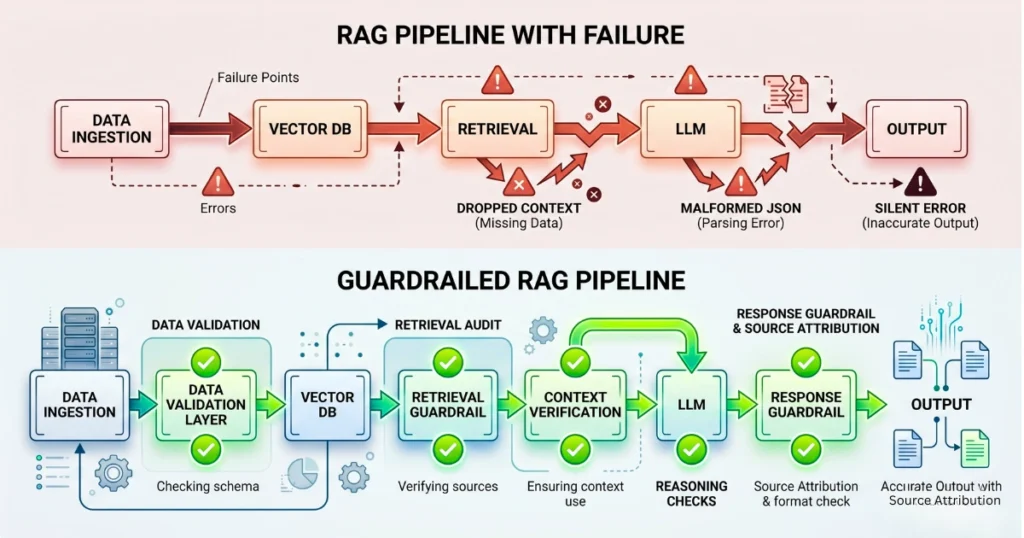
Raw Retrieve and Generate APIs Expose Silent Failures
Moving to an Amazon Bedrock Knowledge Base using Retrieval-Augmented Generation (RAG) fixed the immediate attribution gap. However, it introduced a nasty operational reality.
A malformed JSON schema in the vector index ingestion pipeline caused the Retrieve And Generate API to silently drop context chunks during a weekend batch processing run. The system returned ungrounded answers that the logging layer blindly classified as successful API hits.
Amazon Bedrock manages the end-to-end RAG workflow, but you own the failure modes.
To meet NAIC standards for minimizing hallucinations, the architecture requires explicit source attribution and retrieved text chunks tied to every generated response. You must force the system to pass the exact source identifiers back to the user interface, refusing to render an answer if the metadata payload is null.
Deterministic Rules Must Override Probabilistic Guesswork
Relying on prompt engineering to prevent the system from giving medical advice or specific financial recommendations failed immediately during edge-case testing.
We implemented Amazon Bedrock Guardrails to enforce safety measures directly at the model access layer, blocking denied topics before the payload reaches the LLM.
Guardrails enforce content filters on both user inputs and model outputs to maintain compliance with applicable insurance laws. We paired this with Automated Reasoning Checks to provide a secondary layer of security and accuracy.
Domain experts built deterministic rules that define exact policy administration boundaries, preventing the model from generating unstated assumptions.
Probabilistic models cannot evaluate binary regulatory limits.
Telemetry Deficits Guarantee Audit Failures
NAIC mandates aggressive, continuous monitoring of AI systems. Testing for model toxicity and robustness is a purely academic exercise if production telemetry vanishes the moment an auditor requests historic invocation logs.
We route raw Bedrock data into Amazon CloudWatch to track token counts and API invocations in near-real-time. Furthermore, we mandate AWS CloudTrail logging for every single API activity. These logs dump directly into an Amazon S3 bucket to maintain the required rigorous audit trails.
An S3 bucket full of CloudTrail logs without strict, immutable retention policies is a ticking compliance bomb.



