
I remember the exact moment our “revolutionary” enterprise AI prototype hit the wall last year. We deployed a naive RAG system hooked straight to a premium LLM API without any semantic caching or token management.
Within four days, our inference costs spiked by 4,200%, the provider rate-limited us into oblivion, and the entire production UI froze for our beta testers.
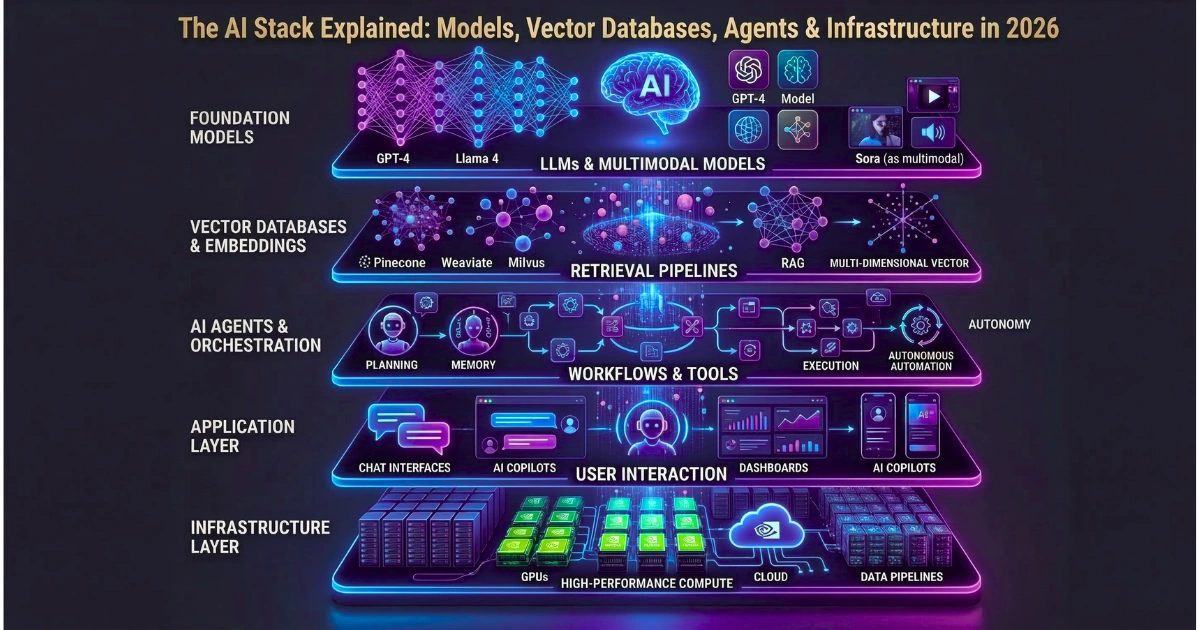
The era of simple, prompt-wrapper applications is dead. Building defensible, profitable applications in 2026 requires mastering the complete AI stack, not just calling a model endpoint. This guide breaks down the shift from model-centric development to a hardened, data-and-agent-centric architecture.
- The myth of the foundation model.
- The 4 core layers of modern architecture.
- Navigating vendor lock-in and maximizing ROI.
Why the 2026 AI Stack Architecture is About Orchestration, Not Just Models
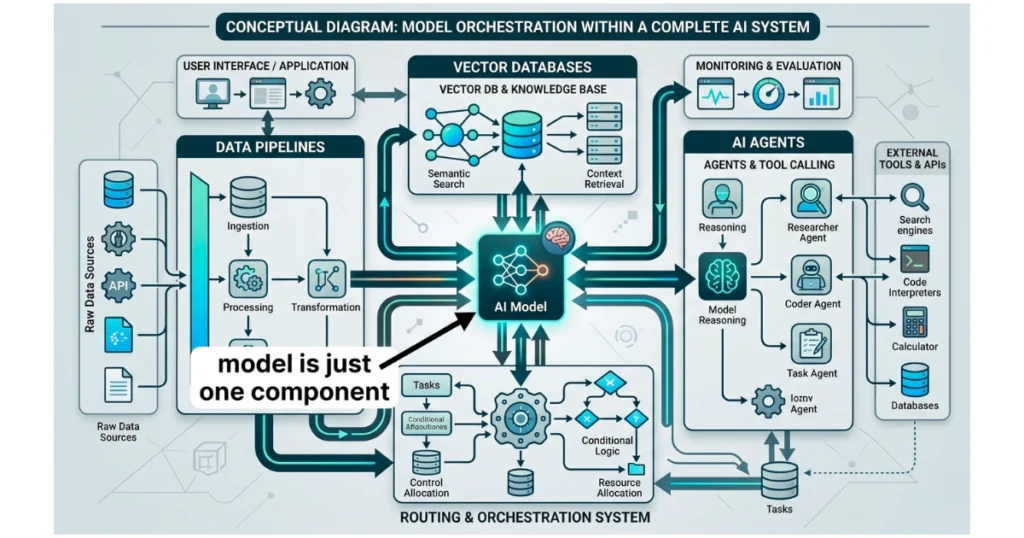
The biggest misconception in our industry right now is that the Large Language Model is the most critical piece of the puzzle. That might have been true three years ago, but today, foundation models are rapidly commoditizing into an interchangeable utility layer.
The real competitive advantage lies entirely in how you orchestrate the surrounding components to manage context and execute actions.
If you spend all your engineering hours agonizing over whether to use GPT-4o or Claude 3.5 Sonnet, you are focusing on the wrong problem.
The engine matters, but it is useless without fuel and a steering mechanism. Your proprietary data pipeline is the fuel, and your agentic orchestration layer provides the steering.
Demystifying the 4 Core Layers of the Modern AI Stack
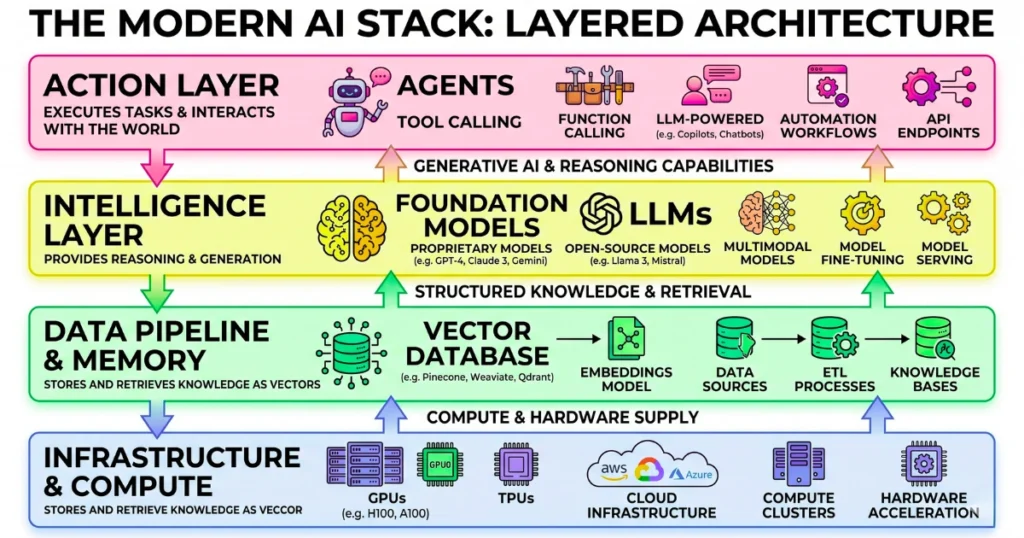
Building a robust, scalable system requires a clean separation of concerns across four distinct layers. Treating these as a monolithic block is a guaranteed recipe for massive technical debt. Let’s break down the actual anatomy of a production-grade enterprise system.
The Infrastructure & Compute Layer: Hosting the Heavy Lifters
Everything starts with the silicon. This layer handles the raw, intensive computation required for both continuous training and high-throughput inference. You are essentially choosing between the massive capital expenditure of on-premise AI hardware for maximum privacy, or the flexible operational expense of managed cloud providers.
The Data Pipeline & Memory Layer: Vector Databases and RAG
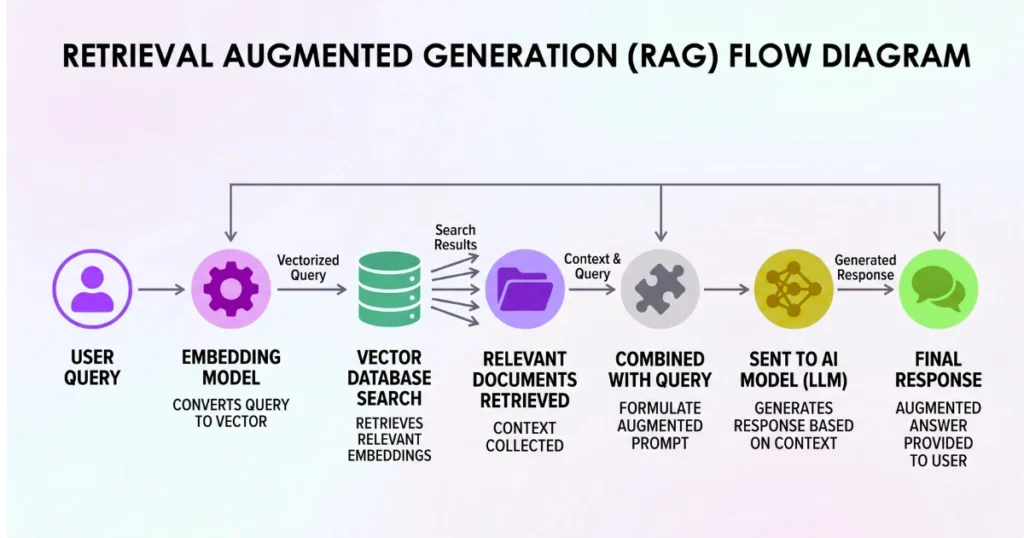
Standard relational databases completely fail at semantic search and nuanced context retrieval. To give your system a reliable long-term memory, you need embedding models and dedicated vector databases. This layer solves the massive, ongoing challenge of ingesting, chunking, and syncing your unstructured enterprise data in real-time.
The Intelligence Layer: Foundation Models and Fine-Tuning
This is where the actual reasoning and linguistic processing happens. The architectural debate here usually centers on relying on proprietary API models versus deploying open-weights models locally. You only need to consider custom LoRA fine-tuning when the financial return of highly specialized task performance clearly outweighs the steep maintenance costs.
The Action Layer: Autonomous Agents, Tool Calling, and Orchestration
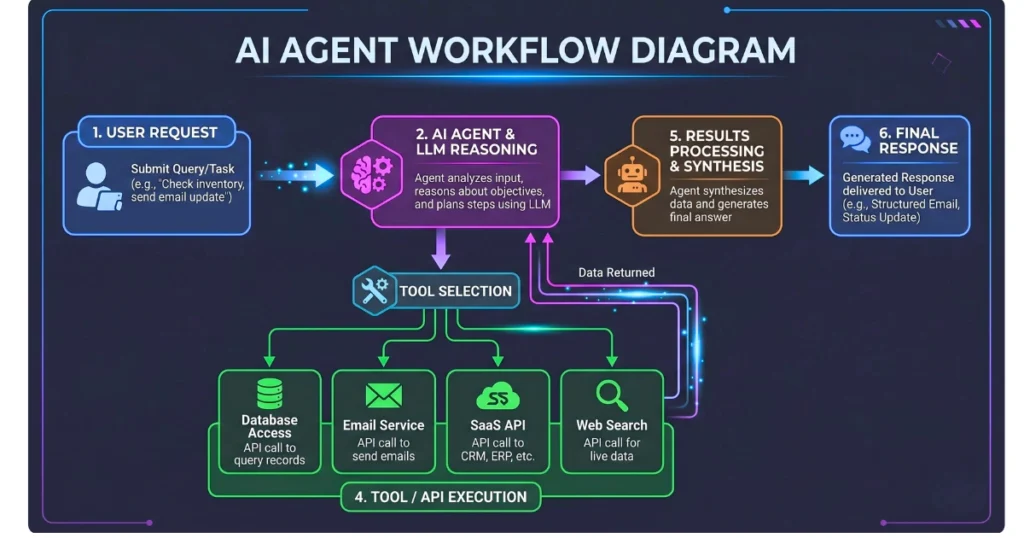
Generating text is no longer enough to deliver real business value. Modern applications must take action by querying proprietary databases, sending emails, or triggering external SaaS workflows. This requires robust orchestration frameworks that safely manage API tool-calling within strict, isolated enterprise environments.
Build vs. Buy: Navigating Vendor Lock-in in the AI Ecosystem
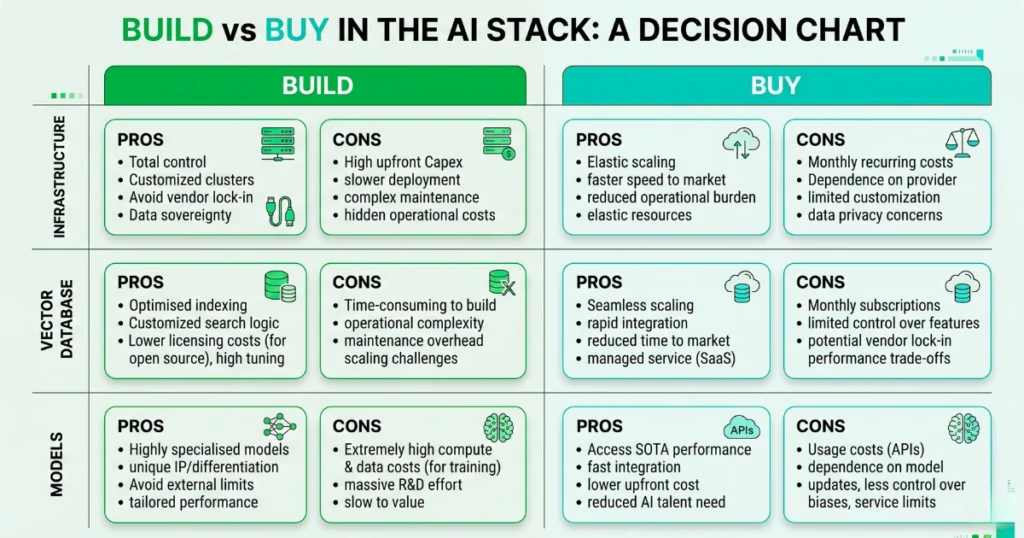
Every engineering leader I consult with is terrified of getting trapped by a single vendor’s rapidly shifting ecosystem. You have to make pragmatic, ruthless decisions about where to spend your budget versus where to burn your engineers’ time. Here is a realistic breakdown of the trade-offs at each layer.
| Stack Layer | Managed Service (Buy) | Open Source / Self-Hosted (Build) |
|---|---|---|
| Infrastructure | Fast deployment, zero hardware maintenance. | Massive CapEx, requires highly specialized ops team. |
| Vector DB | Frictionless setup, usage-based scaling. | Absolute data sovereignty, high engineering overhead. |
| Models | Instant intelligence, severe vendor lock-in. | Complete privacy, complex scaling and latency issues. |
Moving from Pilot to Profitable: Maximizing Enterprise AI ROI
Bridging the gap between a local testing environment and a profitable production release is brutal. The primary obstacle is rarely the intelligence of the model; it is almost always the unit economics of the system.
Calculating the real total cost of ownership means factoring in pipeline maintenance, vector storage fees, and perpetual inference costs.
To actually achieve a positive ROI, you must implement aggressive system optimization strategies.
This means utilizing smaller, task-specific models for routing and basic queries, reserving the heavy-duty models only when complex reasoning is strictly required. It also demands caching identical user queries to bypass the expensive model layer entirely.
Common Pitfalls: Where AI Deployments Fail in Production
My team has audited dozens of failing systems over the last year. The exact same structural errors appear repeatedly across entirely different industries and use cases.
Pitfall 1: Ignoring Data Governance and Security Guardrails
Rushing a prototype to production without hardcoded guardrails is a massive corporate liability. Unfiltered Retrieval-Augmented Generation systems can easily leak sensitive internal financial data or PII to unauthorized end-users. Prompt injection attacks remain a critical vulnerability that basic prompt engineering cannot solve alone.
Pitfall 2: Over-Engineering the Agentic Layer Too Early
I constantly see development teams trying to build complex swarms of autonomous agents before perfecting their basic data retrieval pipelines.
If your foundational semantic search returns hallucinated garbage, your highly sophisticated agent will just confidently execute irreversible actions based on that garbage.
Nail the memory and retrieval layer before you try to build an autonomous digital employee.
Pitfall 3: Underestimating Inference Costs at Scale
This is exactly what killed our early prototype. If you do not implement semantic caching and hard token limits, your API bills will scale exponentially with user adoption. You are actively penalizing your own success if every user click requires a massive, fresh API call to a premium model.
Future-Proofing Your Stack
The vendor landscape of 2026 is going to consolidate rapidly, but the foundational architecture patterns are solidifying right now.
Focus your engineering energy on building clean, modular interfaces between your internal data pipelines and your external models. By keeping your architecture decoupled, you can swap out individual components as faster, cheaper alternatives emerge without having to rewrite your entire application.



