

What AI Actually Does When You Type a Prompt (Explained)
Most people have the wrong mental model of what’s happening when they type something into an AI tool. It feels like you’re asking a system…

Why AI Still Makes Simple Mistakes (And What It Reveals About How AI Works)
The strange thing about working with AI long enough is that you stop being impressed by the big stuff. Generating essays, solving equations, writing code—that…

Open vs. Closed AI Models: Which Will Actually Win in 2026?
The AI industry keeps asking the wrong question. Every week, another benchmark comparison floods social media: But the real production bottleneck in 2026 is no…

AI Memory Explained: Why Chatbots Forget Everything (Hidden Problem)
AI memory failures are not caused by hallucinations. The real problem is far more structural: modern AI systems still struggle to manage state reliably across…
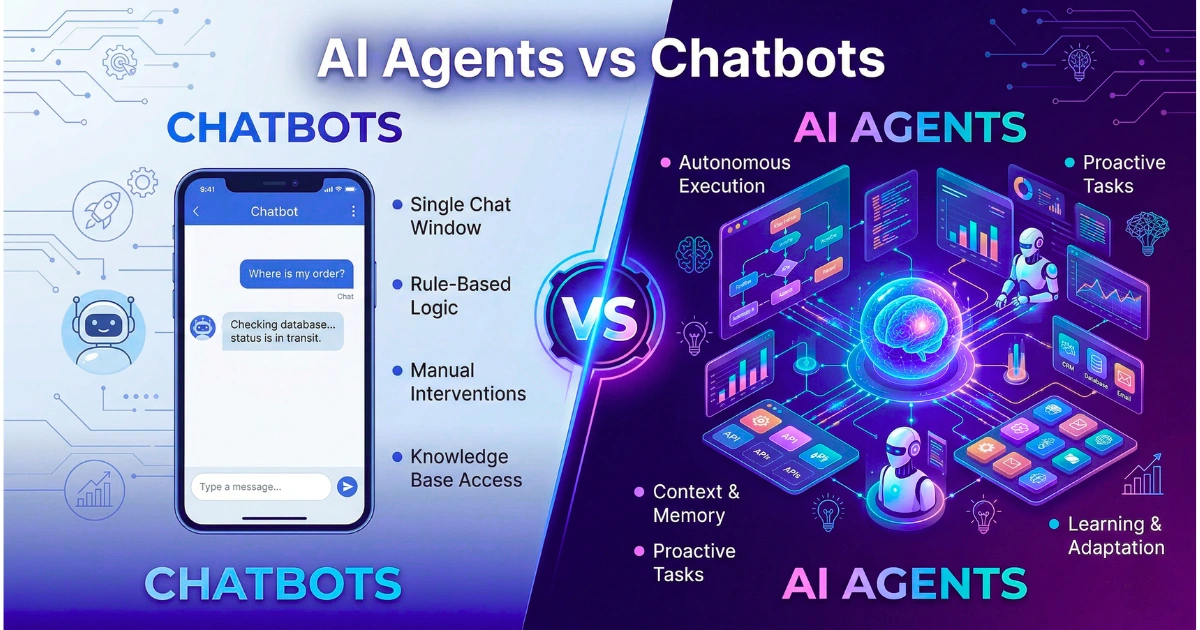
AI Agents vs Chatbots: The Real Difference Explained (2026 Guide)
Chatbots Are Glorified Search Indexes A chatbot waits for a human to type a string. It is a strictly reactive system bound by the latency…




