Exploring AI, One Insight at a Time


AI Hallucinations Explained: Why ChatGPT Sometimes Gets Facts Wrong
The first time I caught ChatGPT confidently making something up, I had to double-check if I was the one missing something. It gave me a clean, well-written answer, even included what looked like a proper reference. The only problem? The source didn’t exist.
That’s when it clicks—this isn’t a rare bug. This is part of how the system behaves.
So what is an “AI hallucination”?
In simple terms, it’s when the model gives you an answer that sounds completely believable… but isn’t actually true. Not obviously wrong. That would be easy to spot. Instead, it’s the kind of answer you’d normally trust:
- A study with realistic authors and formatting
- A quote that feels like something the person would say
- A historical detail that’s just slightly off
The tricky part is that nothing looks broken on the surface.
Why this keeps happening
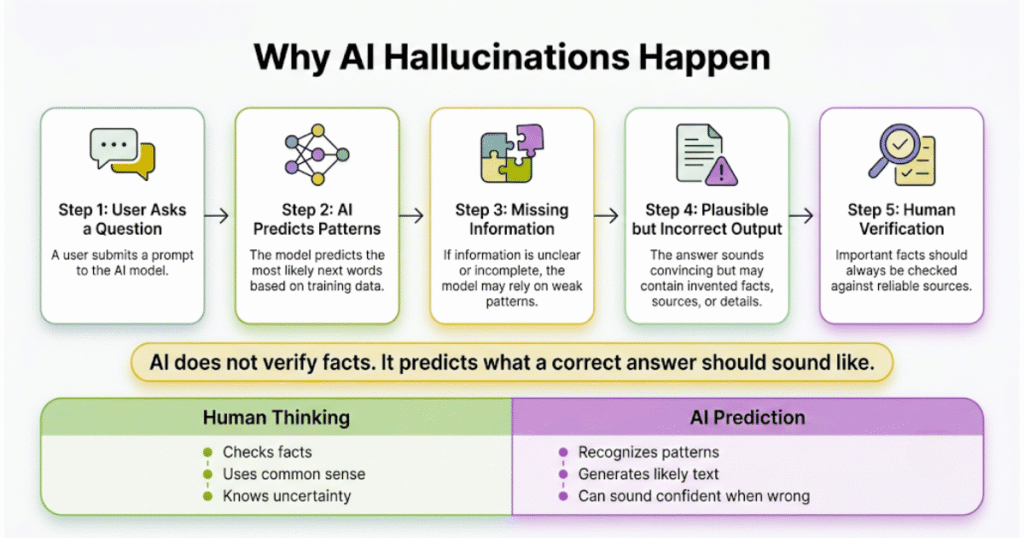
Most explanations make this sound more complex than it is. At its core, the model is just predicting what comes next in a sentence. That’s it.
It doesn’t pause and think, “Is this factually correct?”
It thinks, “What’s the most likely next word here?”
Usually, those two things overlap. Sometimes they don’t. And when they don’t, you get a very confident mistake.
It doesn’t know when it doesn’t know
This is probably the biggest gap. Humans hesitate. We say things like “I think,” or “I’m not sure.” That hesitation is useful—it protects us from saying nonsense.
Models don’t naturally do that.
If there’s even a weak pattern pointing toward an answer, they’ll follow it. And they’ll present it cleanly, without signaling doubt unless explicitly told to. So instead of saying “I’m not sure,” you often get a fully formed answer that just… shouldn’t exist.
Longer answers make it worse
Short replies are usually fine. There’s less room to drift. But once you ask for explanations, breakdowns, or multi-step reasoning, things start to slip.
It’s not one big mistake. It’s small guesses stacking on top of each other. By the time you reach the end, the answer can feel solid—even if the foundation isn’t.
The patterns you start noticing
After a while, certain mistakes stop being surprising. You’ll see things like:
- References that look academic but lead nowhere
- Explanations that sound authoritative but ignore nuance
- Small factual shifts that change the meaning entirely
- Answers that feel “too smooth” for a messy topic
It’s not random. It’s the model trying to stay coherent, even when it’s unsure.
What actually helps (from practical use)
There’s no way to completely remove hallucinations. Anyone claiming that is overselling. But you can reduce them quite a bit.
One approach is grounding the model with real data—basically forcing it to pull from known documents instead of relying only on patterns. That alone cuts down a lot of the guesswork.
Another is narrowing the scope. The more general the question, the more room there is for the model to improvise. Tight, specific prompts usually lead to better answers.
Even small prompt tweaks help. Asking for sources, or telling it to say when it’s uncertain, changes how it responds more than you’d expect.
Why this matters more than people think
The real issue isn’t that the model gets things wrong. It’s that it gets things wrong convincingly.
If an answer sounds weak, people question it. If it sounds polished, they trust it. That’s where mistakes slip through—especially in areas where accuracy actually matters.
So the safest way to use tools like this isn’t blind trust or total skepticism. It’s somewhere in between.
Use it to explore, draft, and think faster. But when something matters—facts, data, decisions—pause and verify. Because the model won’t do that part for you.



